Сегодня разбираем короткую и довольно простую статью о стриминговом Whisper’e. Whisper — это encoder-decoder-модель, и если в стриминге каждый раз прогонять декодер заново на всём аудио, получается слишком дорого. Поэтому авторы предлагают на каждом новом чанке заново прогонять только энкодер, а дальше следить, чтобы декодер не упирался в конец чанка и не начинал угадывать слова неправильно.
Низкий WER degradation
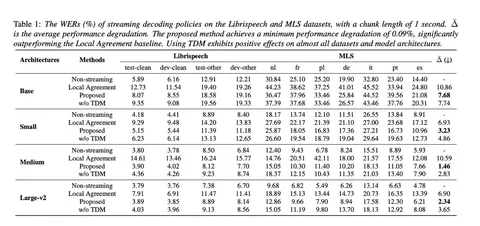
Под WER degradation понимают то, как сильно ухудшается word error rate при переходе от офлайна к стримингу. В таблице выше авторы сравнили разные стратегии: офлайн-бейзлайн, Local Agreement и предложенный метод.
В правом столбце Δ показана средняя деградация — и у нового подхода она самая маленькая: всего 1,46%, то есть качество почти не проседает по сравнению с распознаванием в офлайне.
Почему стриминг ломается на границах чанков
Проблема кроется в архитектуре Whisper. Это Seq2Seq-модель, обученная на полных предложениях. Она всегда стремится выдать законченный, осмысленный текст и не умеет «молчать» или выдавать части слов.
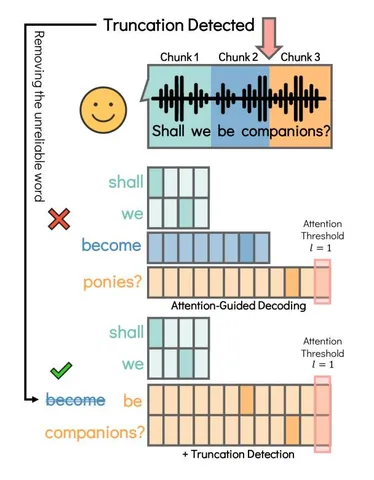
Рассмотрим пример с фразой “Shall we be companions?”, где граница чанка разрезала слово “companions”. Происходит следующее.
1. Акустическая ловушка. Модель получает аудио, которое обрывается на звуке "be com...".
2. Принудительный выбор (Forced Prediction). Модель слышит "be com...". В её словаре токенов (BPE) наиболее вероятным кандидатом для этого звукового паттерна оказывается токен "become". Поскольку модель обучена на завершённых фразах, она стремится «закрыть» акустический паттерн известным ей токеном, вместо того чтобы ждать продолжения (которого в текущем чанке нет).
3. Ошибка токенизации. Как только токен "become" сгенерирован, он становится частью истории. Когда приходит следующий кусок звука "...panions", декодер уже не может отменить предыдущий токен. Пытаясь продолжить текст после "become", декодер подбирает следующий наиболее вероятный токен — "ponies", так как он фонетически похож на входящий звук и хоть как-то согласуется с предыдущим контекстом.
Итог: ошибка возникает из-за того, что модель пытается «додумать» обрезанный край чанка, принимая преждевременное решение, которое потом невозможно исправить.
Решение — метод из двух частей
В статье предлагают подход, в котором одна составляющая определяет, где можно безопасно резать, а другая — когда пора запросить следующий чанк.
1. Truncation Detection Module (TDM), построенный на механизме Integrate-and-Fire (IF). Модель постепенно накапливает некоторую величину по аудиофреймам. Когда накопление превышает порог, происходит “fire” — это считается сигналом, что слово закончилось и здесь можно обрезать. Обучение происходит таким образом, чтобы количество срабатываний совпадало с количеством слов.
2. Attention-Guided Decoding Policy — эта часть выглядит даже более важной. Поскольку Whisper обучался на задаче предсказания таймстемпов (alignment), его карты внимания (attention maps) очень чётко «подсвечивают» тот участок аудио, который соответствует текущему слову. Авторы смотрят, куда «смотрит» модель. Если пик внимания (максимальный вес) приходится на самый конец текущего аудиочанка (последние фреймы), это красный флаг.
- Это значит: «Я пытаюсь декодировать слово, но его аудиопризнаки обрываются на самом интересном месте».
- В этот момент нужно остановить генерацию и ждать следующий чанк.
Результаты
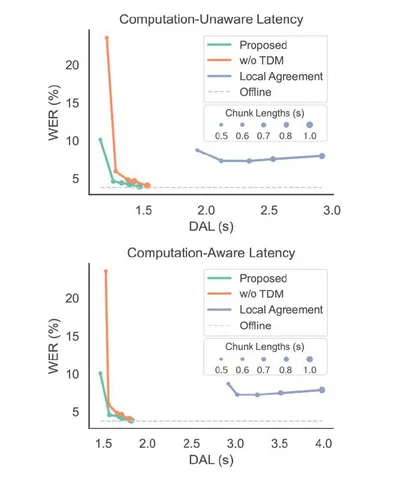
В конце авторы приходят к выводу, что можно сделать стриминговый Whisper, который почти не теряет в качестве, избегает ошибок на границах чанков, работает с меньшей задержкой, чем Local Agreement. Таблица в конце подтверждает, что на больших моделях (Large-v2) метод даёт хороший баланс между скоростью и точностью.
Вилиана Девбунова