Разберём ещё две любопытные работы с Speech Synthesis Workshop. Одна посвящена управлению стилем на уровне слов, другая — синтезу речи с невербальными характеристиками.
Lina-Style: Word-Level Style Control in TTS via Interleaved Synthetic Data
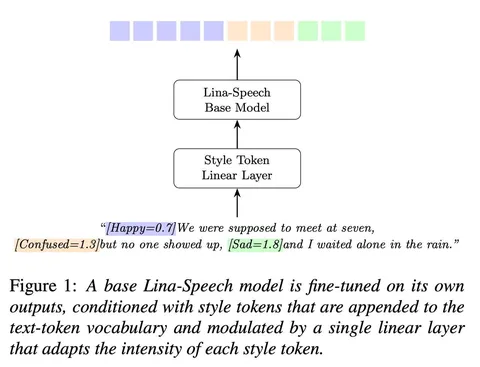
Авторы предложили, как из небольшой выборки с разметкой стиля и большого неразмеченного корпуса построить полностью синтетический датасет с локальными (на уровне слова) метками стиля и его интенсивностью, а затем дообучить модель, чтобы она кондишенилась на метки. Для этого они использовали свою предыдущую работу, модель Lina-Speech. Архитектурно это текстовый энкодер и аудиодекодер с Gated Linear Attention (GLA). GLA, кстати, позволяет легко использовать prefix free prompting через initial state-tuning. Этим и воспользовались авторы.
Сначала они взяли претрейн Lina-Speech на неэмоциональной речи. Дотюнили его через initial state-tuning на несколько стилей (neutral, happy, confused, enunciated). Затем синтезировали несколько вариантов одной и той же реплики в разных стилях. Во время синтеза также использовали classifier‑free guidance (CFG), случайно сэмплировали альфа, поэтому насинтезированные аудио получились в разных стилях и с разной их интенсивностью.
Для каждого аудио построили соответствие текста аудиотокенам. Для этого извлекли матрицы soft-алайнмента текста и аудио и превратили их в матрицы hard-алайнмента с помощью Monotonic Alignment Search (MAS). Таким образом получили соответствие токенов аудио отдельным словам. Склеили слова из разных стилей в одно предложение и получили синтетический интерливинг-датасет с word-level-разметкой на стиль.
Осталось затюнить итоговую модель. На этом этапе дообучили базовый претрейн, добавив новые параметры: эмбеддинги стилей, интенсивностей и linear для их комбинации.
Почему это круто
Потому что это — пример сбора синтетического датасета с локальными метками стиля с нуля. В изначальном датасете сэмплов с word-level-разметкой не было. Ну и успешное обучение на синте подтвердило, что метод рабочий. Позалипать на сэмплы можно тут.
NonverbalTTS: A Public English Corpus of Text-Aligned Nonverbal Vocalizations with Emotion Annotations for Text-to-Speech
Янднекс тоже привёз свою статью, написанную совместно с коллегами из VK Lab. В ней предложили датасет для синтеза речи с невербальными характеристиками на английском языке и рассказали о пайплайне его сбора. Невербальные характеристики — это смех, вздох, кашель и другие звуки, которые мы издаём в речи и которые не являются словами.
В реальной жизни таких невербальных характеристик много, но разметки для них часто нет. Авторы взяли два опенсорсных датасета — Expresso и VoxCeleb — и сначала с помощью опенсорсных моделей получили грубую разметку по невербальным характеристикам и эмоциям. Затем уточнили результаты с помощью ручной разметки и отфильтровалы шумные сэмплы (например, аудио со смехом, который оказался закадровым). После этого зафьюзили варианты правильных транскрипций от нескольких разметчиков и получили итоговый датасет: 13 часов аудио с 10 типами невербальных характеристик.
Затюнили на своём датасете CosyVocie и сравнились с CosyVoice2, который обучался на проприетарном датасете, нестатзначимо проиграли в SbS. В статье раскрыли детали пайплайна разметки, а датасет выложили на Hugging Face. Там немного, но это честная работа.
Почему это круто
Синтез с невербальными характеристиками нужен для синтеза спонтанного и разговорного стилей речи. NVTTS может быть использован для файнтьюна, а также как стартовая точка для скейла и unsupervised-разметки датасета большего размера.
Дарья Дятлова