Сегодня начинаем разбирать свежую статью на тему аудиочаптеринга. Задача аудиочаптеринга — разбить запись на смысловые куски (чаптеры), чтобы каждый соответствовал какой-то теме или логическому блоку.
Обычно сначала прогоняют аудио через ASR, получают транскрипт, а потом делают текстовую сегментацию — например, с помощью LLM. Авторы статьи предлагают другой подход: попробовать делать чаптеринг напрямую по аудио, без обязательной опоры на текст.
В работе сравнивают три подхода:
1) классический текстовый чаптеринг;
2) AudioSeg — audio-only-подход, который предлагают авторы;
3) использование мультимодальных моделей.
Задача текстовой сегментации формулируется так. Есть транскрипт, разбитый на предложения. Для каждого предложения нужно предсказать, является ли оно концом чаптера.
Чтобы сравнить предсказания с референсом, предложения сначала алайнятся по времени. Тут есть несколько вариантов:
- по референсному тексту через forced alignment;
- по ASR-транскрипту;
- алайнмент по токенам;
- алайнмент по временному пересечению предложений.
После этого границы можно мапить в тайминги референса и считать метрики. Основные метрики такие:
Pk — смотрим пары предложений и проверяем, правильно ли модель определила, находятся они в одном чаптере или в разных.
Boundary Similarity — что-то вроде редакторского расстояния между последовательностями нулей и единиц, обозначающими границы чаптеров.
Авторы также предлагают временные метрики, которые вообще не используют текст. Есть два варианта:
T1 (time-based discrete) — аудио разбивается на равные чанки. Смотрим, в какие из них попадают референсные и предсказанные границы. Авторы репортят почти все результаты именно по этому протоколу.
T2 (time-based continuous) — уже настоящий вариант с непрерывными таймстемпами. Если предсказанная граница попадает в небольшой интервал вокруг референсной (collar), считаем её true positive и по ним считаем F1.
Подходы
1. Text-Based baseline. Берут предложения из транскрипта, кодируют их sentence encoder’ом, получают эмбеддинги и подают в трансформер (RoFormer). На каждом предложении решается бинарная задача: конец чаптера или нет. К тексту также добавляют аудиофичи: длину пауз, скорость речи, pitch, громкость, смену спикера и т.д. Их конкатенируют с эмбеддингами предложений.
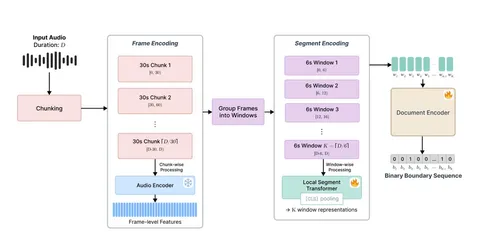
2. AudioSeg — основной метод авторов. Пайплайн состоит трёх уровней: frame encoding, segment encoding и document encoding.
Аудио сначала режут на 30-секундные чанки и прогоняют через замороженный предобученный аудиоэнкодер (например, Whisper). Получаются фреймовые эмбеддинги. Дальше их группируют в 6-секундные окна. Каждое окно обрабатывается трансформером и превращается в один эмбеддинг сегмента.
Получается последовательность сегментных эмбеддингов, которая подаётся в документный трансформер. Он предсказывает, является ли окно концом чаптера.
Во второй части разбора расскажем об аблейшнах и выводах, к которым пришли авторы.
Даниил Волгин