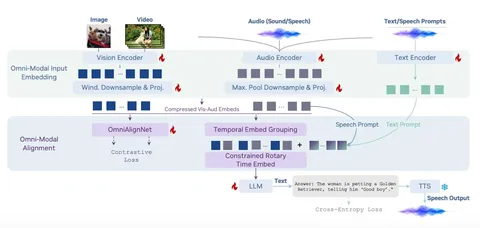
Сегодня начинаем разбирать статью, представляющую OmniVinci — мультимодальную LLM от Nvidia, сравнимую по качеству с SOTA-моделями на бенчмарках всех модальностей. Главным вкладом своей работы авторы считают не столько численные результаты на бенчмарках, сколько тот факт, что в техрепорте они объясняют все дизайн-решения, связанные с архитектурой модели и сбором данных для тренировки. Одно из таких экспериментально подтвержденных решений — использование в качестве аудиоэнкодера энкодера из Audio Flamingo 3 (альтернативой выступал аудиоэнкодер Qwen2.5). Но особое внимание авторы уделяют трём идеям: OmniAlignNet, Temporal Embedding Grouping и Constrained Rotary Time Embedding — о них и пойдёт речь в посте.
OmniAlignNet
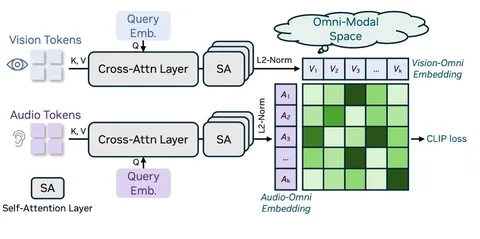
В процессе обучения модели каждое видео разбивается на аудиопоток и поток изображений; при этом семантически эти потоки связаны, так как звук может дополнять картинку (и наоборот). Чтобы аудиоэмбеддинги и эмбеддинги картинок были в одном латентном пространстве, модели и нужен модуль OmniAlignNet.
Общий пайплайн работы модуля выглядит следующим образом:
1) для аудиального и визуального потоков получаем последовательность эмбеддингов;
2) используем эти последовательности как key-value-эмбеддинги для cross attention; смешиваем их с query-эмбеддингом (свой для каждого потока) и получаем для каждого видео два мультимодальных эмбеддинга (audio-omni и visual-omni);
3) мультимодальные эмбеддинги прогоняем через три self-attention-слоя и L2-норму;
4) для батча мультимодальных эмбеддингов максимизируем кросс-модальное расстояние (скалярное прооизведение) для эмбеддингов, соответствующих разным сэмплам, и минимизируем в обратном случае (для эмбеддингов, соответствующих одинаковым сэмплам) — contrastive loss, похожий на то, что было в CLIP (симметричная кросс-энтропия из vision в audio и наоборот).
OmniAlignNet хорошо справляется с моделированием верхнеуровневых семантических связей между аудиальными и визуальными эмбеддингами. При этом для того, чтобы моделировать более низкоуровневые связи, авторы предлагают два вида преобразования эмбеддингов, речь о которых пойдет дальше.
TEG: Temporal Embedding Grouping
Идея TEG в том, что правильное упорядочивание эмбеддингов разных модельностей помогает языковой модели лучше улавливать локальные смысловые зависимости. Гиперпараметр этого метода — размер временного окна T_g, которое контролирует гранулярность группировки эмбеддингов: эмбеддинги делятся на чанки размером T_g; модальности внутри чанков чередуются.
Авторы утверждают, что такая гранулярная конкатенация эмбеддингов улучшает качество модели по сравнению с подходом, где эмбеддинги конкатенируются крупными блоками (блок vision → блок audio → блок vision…).
Constrained Rotary Time Embedding (CRTE)
CRTE — это модификация Rotary Time Embeddings (RoTE, не путать с RoPE), трёхстадийный процесс, состоящий из генерации базовых частот, модификации этих частот и rotary-части, т.е. поворота эмбеддингов.
На этапе генерации базовых частот в CRTE предлагается добавить гиперпараметр T_max — этот множитель добавляется в знаменатель при вычислении базовых частот. Чем меньше T_max, тем больше учитываются близкие друг другу эмбеддинги (и наоборот): w_i = 2π/(T_max·θ^(i/C)).
На этапе модификации базовых частот CRTE продолжает идею RoTE: для определения углов поворота эмбеддингов используются настоящие расстояния в секундах, в отличие от дискретных позиций у RoPE: Ω_{i,j} = ω_i · t_j, где t_j — реальная временная метка.
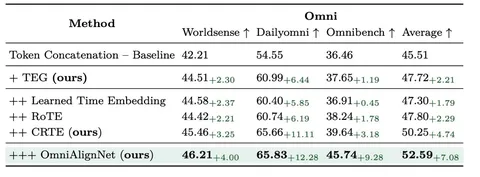
Авторы проводят ablation study и доказывают, что все предложенные модификации действительно улучшают качество модели на мультимодальных бенчмарках (см. третий скриншот).
В продолжении разбора мы подробнее расскажем, какие ещё эксперименты были проведены авторами статьи, а также о разнице между implicit learning и explicit learning у мультимодальных моделей.
Екатерина Козлова