Разбираем статью о Vevo2 — унифицированной модели для генерации контролируемой речи и пения. Цель авторов — создать гибкий механизм независимого управления текстом, просодией (мелодией), стилем (акцентом, эмоциями, вибрато) и тембром для обеих модальностей. В этом посте разберём вклад, который работа вносит в индустрию.
Вклад в данные для пения
Во-первых, авторы решают проблему дефицита аннотированных данных для пения. Предлагаются два аудиотокенизатора (не требующих ручной аннотации для музыкальных данных):
— Prosody Tokenizer (6.25 Гц) — VQ-VAE, обучаемый на реконструкции хромаграммы; кодирует просодию речи, мелодию пения и даже инструментальных звуков.
— Content-Style Tokenizer (12.5 Гц) — VQ-VAE, реконструирующий хромаграмму и скрытые состояния Whisper; кодирует лингвистический контент, просодию и стиль для речи и пения, устойчив к различному тембру, что авторы демонстрируют результатами в Voice Conversion.
Выбор хромаграммы с низкой частотой обусловлен простотой расчёта, устойчивостью к шуму и различным источникам, а также octave-free-представлением (снижает разрыв диапазона F0 между речью и пением).
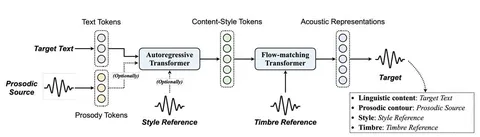
Архитектура Vevo2 включает два этапа:
1. Авторегрессивное моделирование Content-Style-токенов (AR-трансформер, инициализированный Qwen 2.5 (0,5B):
— На вход принимает текст + (опционально) Prosody-токены + Content-Style токены референса.
— Поддерживает Explicit Prosody Learning (EPL) (просодия как явный ввод) и Implicit Prosody Learning (IPL) (просодия генерируется in-context).
— Во время претрейна стратегии EPL/IPL чередуются равновероятно для всех данных — это унифицирует обучение речи и пения.
2. Акустическое моделирование (Flow-Matching):
— Преобразует Content-Style-токены в мел-спектрограмму, обуславливаясь на референс тембра.
— Финальный waveform — через Vocos-вокодер, дообученный на речь и пение.
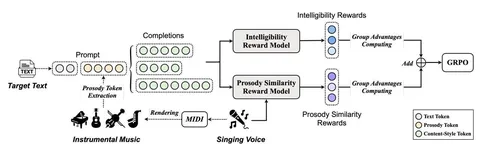
Вклад в пострейн (GRPO)
Этот этап нужен для повышения разборчивости речи и просодической схожести с контролирующей последовательностью, а также для обобщения на инструментальные источники мелодии.
Используется сумма двух наград:
— Intelligibility Reward: обучается на контрастив хороших-плохих пар (текст, Content-Style токены). Стратегии EPL/IPL как и на претрейне чередуются равновероятно.
— Prosody Similarity Reward: косинусная близость между хромаграммой ground-truth и реконструкцией (через декодер Content-Style Tokenizer) из сгенерированных Content-Style-токенов.
Унифицированное моделирование даёт взаимные преимущества: обилие речевых данных улучшает качество пения, пение — выразительность и просодический контроль речи. Vevo2 достигает SOTA в SVS, SVC, humming-to-singing, instrument-to-singing и близких к лучшим результатов в TTS/VC.
Дмитрий Попов