Во второй части обзора статьи мы подробно поговорим о тренировке модели и разберём разницу между implicit и explicit learning.
Обучение модели
Обучение модели можно разделить на два больших этапа — modality-specific и omni-modal части соответственно, LLM-backbone при этом берётся предобученная (авторы используют Qwen2.5-7B-Instruct).
Обучение vision-модулей состоит из следующих стадий:
- Stage 1: Vision Projector Alignment — учится только vision-проектор, решается задача генерации простых описаний.
- Stage 2: Vision Encoder Alignment — учатся vision-энкодер и vision-проектор.
- Stage 3: Vision Pre-training — core-стадия, vision-энкодер заморожен, цель — finetune vision-проектора и LLM. Используются мультимодальные данные, модель учится интерпретировать и генерировать подписи к картинкам.
- Stage 4: Image Instruction Tuning — finetune модели на задачи vision instruction following: ответы на общие и knowledge-based-вопросы, генерация сложных подписей, logical и vision reasoning, интерпретация документов, обработка диаграмм, etc. Учатся все модули.
- Stage 5: Video Instruction Tuning — финальная стадия, все части модели учатся на задачу понимания видео (распознавание активности (activity recognition); трекинг объекта во времени (по фреймам), time-sensitive QA). Цель — получить у модели способность к temporal reasoning.
После vision-этапа авторы получают «vision preliminary checkpoint» — достаточно хорошо обученные на vision-задачи энкодер, проектор и LLM.
Обучение аудиомодулей делится на две стадии:
- Stage 1: Audio Projector & Encoder Alignment. Параметры LLM и vision-части заморожены, учимся на задачи audio-based QA, captioning, ASR. Цель — обучить проектор аудиопредставлениям, согласованным с семантическим пространством языковой модели.
- Stage 2: Audio Instruction Tuning: параметры LLM не заморожены, LLM учится вместе с аудиоэнкодером и аудиопроектором. Учимся на все те же задачи + на задачу перевода речи; идея стадии в том, что разнообразные аудиальные задачи при обученном проекторе помогут аудиоэнкодеру выучить и низкоуровневые акустические признаки, и высокоуровневые семантические представления.
Omni-Modal Joint Training
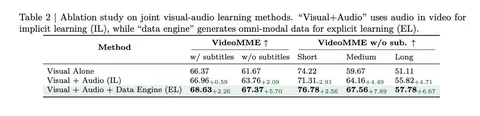
Во время мультимодального этапа обучения vision- и аудиоэнкодеры заморожены, учатся все остальные модули (OmniAlignNet, проекторы и LLM). В статье описываются два подхода: implicit и explicit learning. Implicit learning использует существующие датасеты Video QA, где модель неявно учится интегрировать обе модальности, не получая однозначной информации о том, какая часть ответа взята из видеоряда, а какая — из звука. Explicit learning использует синтетические данные, в которых указывается взаимосвязь между модальностями. Главная разработка авторов — data engine, генерирующий отдельные описания для видео и аудио, а затем использующий LLM с ризонингом (Deepseek R1) для создания объединенных подписей, указывающих на то, как визуальная и аудиальная информация дополняют друг друга. Проблема, которую решает этот подход — устранение «modality-specific hallucination» (fig 1). Ключевой вывод мультимодальной стадии: описание видео, основанное на одной модальности, часто неточно; интеграция обеих модальностей критична, и explicit learning эффективно решает эту задачу (fig 2).
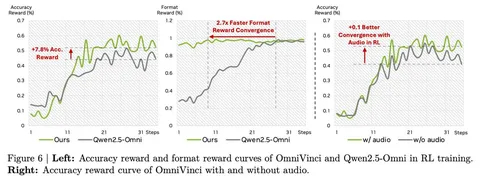
Финальная стадия обучения включает RL с использованием GRPO. Важный результат: GRPO на audio-visual-данных сходится быстрее и качественнее, чем на чисто визуальных, что подтверждает ценность мультимодального подхода (fig 3).
Заключение
В статье OmniVinci представлен комплексный подход к созданию мультимодальных языковых моделей, включающий архитектурные инновации и продуманную стратегию обучения с разделением на modality-specific- и omni-modal-этапы. Ключевой вклад — систематическое исследование подходов к мультимодальному обучению. Авторы демонстрируют, что explicit learning с синтетическими данными эффективнее решает проблему modality-specific hallucination и улучшает общее качество модели.
Екатерина Козлова