Сегодня разберём статью о Bournemouth Forced Aligner (BFA) — достойном преемнике знаменитого Montreal Forced Aligner (MFA).
Forced Alignment — это процедура определения временных границ фонем в аудио. Долгое время популярным решением был точный, но медленный MFA на HMM-GMM. Современные нейросетевые решения, вроде WhisperX, быстрее, но часто уступают старичку MFA в качестве. Приходится выбирать: либо скорость, либо точность. Новая статья о BFA предлагает решение этой проблемы.
Что под капотом
1. Contextless Universal Phoneme Encoder (CUPE). Энкодер анализирует акустику каждого фрейма «без контекста», то есть независимо от соседних фонем. Это ключевое отличие от классических моделей, использующих трифоны, и одна из главных причин прироста скорости. Универсальность достигается за счёт обучения на широком наборе фонем из разных языков (LibriSpeech, MLS), что позволяет модели отлично обобщаться. Авторы показали, что модель, обученная на семи европейских языках (без английского), успешно справляется с выравниванием английской речи.
2. CTC-декодер. CTC-алгоритм выравнивает последовательность фонем относительно аудио, но авторы модифицировали его для forced alignment. Целевая последовательность для декодера строится как [blank, p1, blank, p2, ...]. Эти blank-токены между фонемами используются для явного моделирования пауз и межфонемных промежутков.
3. Multi-task-обучение. Используется архитектура с двумя головами: одна для 67 классов фонем, другая для 17 укрупнённых фонемных групп.
Что это даёт на практике
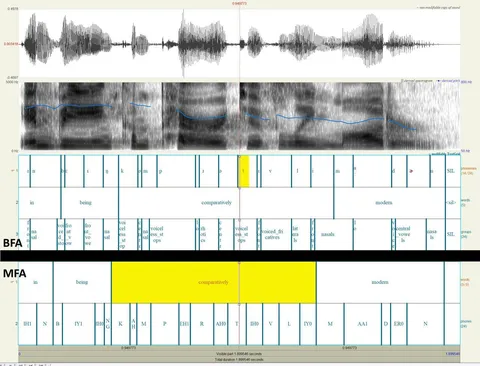
Предсказание onset и offset. Это главная фишка. BFA предсказывает не только начало, но и конец каждой фонемы, что позволяет моделировать межфонемные паузы в отличие от традиционных алайнеров.
Отличная скорость. За счёт бесконтекстной архитектуры BFA работает до 240 раз быстрее MFA. Например, обработка корпуса Buckeye занимает 1 час против 7 дней у MFA.
Умный декодинг. Система использует иерархический подход (divide-and-conquer), разбивая аудио по найденным паузам на независимые сегменты и выравнивая каждый отдельно. Специальный постпроцессинг гарантирует, что 100% фонем из транскрипции будут найдены и расставлены в аудио.
Что по метрикам
Recall у BFA сопоставим с MFA, особенно на разумных порогах в 40–60 мс. Precision получился чуть ниже, но авторы заявляют, что это ожидаемый эффект: BFA предсказывает вдвое больше границ (onset + offset), а сравнивается с эталонной разметкой, где есть только onset.
И да, название BFA выбрано не случайно: авторы продолжают традицию называть форс-алайнеры в честь города или университета, где над ними ведётся основная работа. Так Montreal Forced Aligner был связан с Монреалем, а Bournemouth Forced Aligner назван в честь Борнмута.
Владимир Гогорян