Сегодня начинаем разбирать техрепорт Qwen 3 Omni — самого нового мультимодального Qwen. Авторы заявляют, что модель достигает SOTA-результатов или близких к ним сразу на всех типах данных. Качество не ухудшается ни в одном направлении по сравнению с немультимодальными моделями Qwen. Другими словами, Qwen 3 Omni показывает качество на тексте не хуже, чем текстовая версия Qwen 3 или визуальная Qwen 3-VL, при сопоставимых размерах моделей.
Из интересных нововведений: модель умеет обрабатывать очень длинные входы — до 40 минут. Также она поддерживает большое количество языков: как для взаимодействий текстом (119), так и в задачах speech-understanding (19) или speech-generation (10). В статье отмечается, что улучшен ризонинг независимо от модальности входа, а latency остаётся низкой — всё работает достаточно быстро.
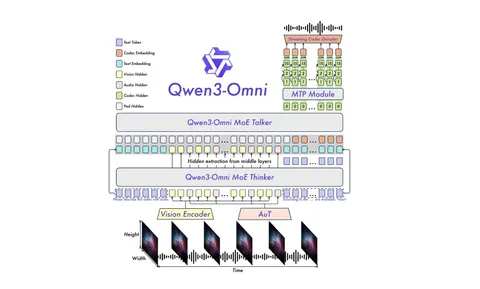
Идейно Qwen 3 Omni очень похож на Qwen 2.5 Omni:
— Используется Thinker-Talker-архитектура. Thinker — языковая модель, которая умеет принимать на вход данные разных модальностей и выдавать текст. Talker принимает выходы Thinker и генерирует аудио. Важное отличие от предыдущего Qwen в том, что теперь Thinker/Talker — это MoE-модели (Mixture of Experts).
— Разные модальности кодируются за счёт соответствующих энкодеров. В Qwen 3 Omni эти энкодеры обновили: для картинок вместо Qwen 2.5 VL используется Qwen 3 VL, а для аудио авторы обучили свой энкодер с нуля.
Одно из основных отличий новой модели от 2.5 Omni заключается в том, как выходы Thinker подаются в Talker. Для изображений и аудио по-прежнему используют хиддены Thinker для соответствующих модальностей, а вот текст теперь передаётся в виде обычных текстовых эмбеддингов. По словам авторов, эмбеддинги уже достаточно хорошо отражают текст, а скрытые состояния избыточны. Такой подход делает систему гибче: можно использовать разные промпты для Thinker и Talker или добавлять дополнительный контекст (например, через RAG), не ухудшая качество.
Как уже упоминалось, в статье используется новый аудиоэнкодер: вместо дообучения Whisper, авторы обучают свою encoder-decoder-модель с нуля. Из интересного в плане архитектуры можно выделить более сильный downsampling factor: 8 вместо 4 (то есть применяется более сжатое представление в аудиомодальности, фреймы по 80 мс вместо 40 мс).
Для обучения под разные задачи использовали 20 млн часов аудио. Из них 80% — задача ASR на китайские и английские псевдолейблы, 10% — задача ASR для других языков и ещё 10% — задача audio understanding. Во время обучения используется window attention с разными размерами окна, чтобы модель могла одинаково хорошо работать и в офлайн-сценариях (с большим контекстом), и в стриминговом режиме (с коротким). После обучения декодер выбрасывается, а энкодер используется для кодирования аудио в самом Qwen 3 Omni.
Основное изменение для видеомодальности заключается в том, как видео подаётся на вход модели. Теперь изображения и аудио чередуются не фиксированными двухсекундными блоками, как раньше, а динамически — в потоке, с гибким соотношением кадров, что делает мультимодальный стриминг более естественным.
В следующей части поговорим о том, как в новой модели поменялась генерация аудио, как проходило предобучение и что авторы говорят о результатах.
Александр Паланевич