Две статьи от Meta* с ICASSP 2025 показывают, как сократить число вызовов декодера в ASR: в одной модель сразу предсказывает несколько токенов, в другой — принимает только те, у которых логиты выше порога. Разбираем, как устроены эти методы и как они влияют на скорость и WER.
Efficient Streaming LLM for Speech Recognition
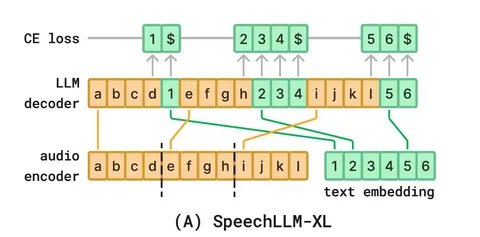
Статья о стриминговой ASR-модели SpeechLLM-XL. Её архитектура состоит из двух компонентов: аудиоэнкодера и LLM-декодера. На вход декодеру одновременно подаются выходы аудиоэнкодера (как в обычной ASR) и токены, которые декодер уже успел предсказать.
В обычном последовательном предсказании на вход сразу передаются звуковые токены, а затем модель догенерирует предсказание по одному токену — и каждый раз сгенерированный токен добавляется ко входу. Таким образом модель работает в decoder-only-режиме.
Основная сложность со стримингом в том, что нужно попеременно передавать новый полученный звук и текстовые токены, которые предсказала модель. Это делается следующим образом. Во время инференса модель обрабатывает аудио по чанкам. После каждого декодер может сгенерировать не один токен, а сразу несколько — пока не встретит специальный маркер конца предсказания. Это позволяет системе работать в стриминге и не откладывать вывод до самого конца. Такой режим авторы реализуют через модифицированную схему тренировки, где модель учат предсказывать текст по частичному аудиоконтексту.
Особенность SpeechLLM-XL — в устройстве генерации: в каждый момент LLM-декодер видит и текущий аудиочанк, и собственные предыдущие предсказания. Это позволяет ему лучше моделировать зависимость между звучанием и текстом, особенно в условиях ограниченного контекста.
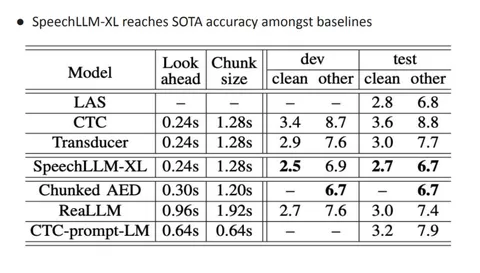
Авторы сравнивают свою модель с другими стриминговыми ASR-решениями. По качеству SpeechLLM-XL обходит все перечисленные в работе бейзлайны на dev-наборах LibriSpeech. Например, на clean-части она показывает WER 2,5% против 2,9% у Transducer и 2,7% у ReaLLM при схожем размере чанка и lookahead — хотя сложно не заметить, что в целом скоры у бейзлайнов великоваты.
Faster Speech-LLaMA with Multi-token Prediction
Авторы пытаются ускорить LLM-декодер в ASR. Идея в том, что вместо генерации одного токена за раз, как в обычной LLM, они учат декодер предсказывать сразу несколько токенов. Чтобы не вызывать LLM отдельно для каждого из них, добавляют в декодер несколько «голов» — по числу токенов, которые нужно предсказать. Эти головы работают параллельно: каждая предсказывает свой токен, зная предыдущие.
Получается схема из трёх шагов:
1) Predict: модель сразу предсказывает K токенов.
2) Verify: среди них ищем самую длинную префикс-последовательность, которую можно подтвердить более строгим one-step-декодером.
3) Accept: принимаем только подтверждённые токены и продолжаем с новой гипотезой.
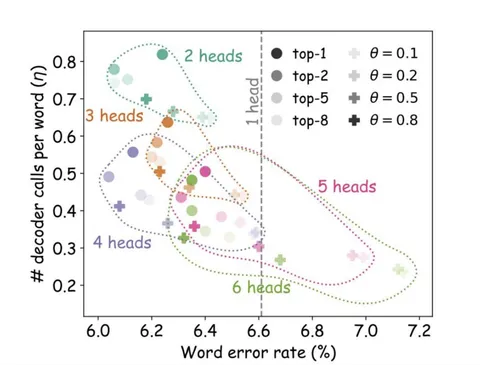
Это позволяет сократить число вызовов декодера без сильной потери качества. На графике видно, как число вызовов на слово (ось Y) падает, особенно при 4–6 головах, а качество (WER по оси X) остаётся на уровне. Лучший компромисс — 4 головы: ускорение ×2, при этом WER почти не растёт.
Верификацию авторы реализуют двумя способами:
— по порогу вероятности;
— по позиции гипотезы в top-N (например, если гипотеза оказалась в топ-5, то её можно принять).
Интересно, что при увеличении числа голов качество даже немного улучшалось. Хотя авторы отмечают это только на LibriSpeech, а на других датасетах наблюдается небольшая просадка.
По сути, это доработка идеи DeepSeek: там тоже пробовали multi-token prediction, но здесь её применили именно в ASR.
Алексей Рак
* Компания Meta признана экстремистской; её деятельность в России запрещена.