Можно ли выучить выравнивание между аудио и текстом без архитектур вроде RNN-T и без использования blank-токенов? Авторы этой статьи считают, что можно. Достаточно self-attention-энкодера с отдельной головой, которая решает, на каких шагах нужно выпускать токены.
Классические ASR-модели (RNN-T, AED) формируют выравнивание во время декодирования: логиты зависят от возможных переходов по временной оси. Это требует либо динамического программирования (в CTC), либо перебора всех допустимых путей (в RNN-T). В Aligner-Encoder модель учится решать, стоит ли выпускать токен на каждом аудиофрейме. В энкодер добавляют FF-слой (aligner head), обучаемый по меткам из CTC loss. Принудительное выравнивание не требуется.
Токены добавляются только тогда, когда aligner говорит «да» — без использования blank-символов или графа выравнивания. Модель не создаёт лишних гипотез, декодинг упрощается, сложность по памяти — существенно ниже: O(U×Vocab) против O(U×T×Vocab) у RNN-T.
Что касается архитектуры, энкодер состоит из 2D-свёрток и Conformer-блоков (FFN, multi-head attention, 1D conv, residuals). Вход — log-mel-спектрограммы (окно 32 мс, шаг 10 мс), токены — WordPiece, используется label smoothing (δ = 2/V), чтобы избежать смещения к коротким предсказаниям.
Начиная с 14-го слоя self-attention, первые текстовые токены начинают фокусироваться на соответствующих аудиофреймах — это можно проследить по диагональному паттерну. Модель при этом «сдвигает» важные представления ближе к началу, сохраняя порядок токенов. В обычных энкодерах такого сдвига не происходит.
Модель обучалась на трёх англоязычных датасетах:
— LibriSpeech (960 часов),
— Voice Search,
— YouTube (670 тысяч часов псевдозаписей длиной 5–15 секунд).
Для оценки на YouTube выделили 30 часов 8-минутных аудиофрагментов (по 15 часов на валидацию и тест). Модель показывает точность на уровне CTC-базлайна на LibriSpeech и превосходит его на YouTube.
Авторы также проверяют, можно ли использовать обученный aligner в других моделях. В одном из экспериментов инициализируют RNN-T слоями из выученного энкодера и получают улучшение по метрикам. Это показывает, что aligner-head может использоваться как самостоятельный механизм выравнивания.
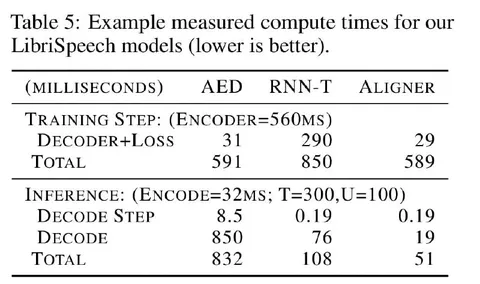
Несмотря на то, что в названии статьи сделан акцент на выравнивание, главная польза модели — в скорости и простоте. В сравнительном эксперименте все модели были одного размера (100 млн параметров). На обучении Aligner оказался в 10 раз быстрее RNN-T (29 мс против 290 мс на шаг), главным образом за счёт отказа от сканирования по временной оси в join-сети. Это также позволило снизить пиковое потребление памяти на 18 % (−1.4 ГБ). На инференсе модель тоже самая быстрая: каждый шаг декодера занимает 0,19 мс против 8,5 мс у AED. Общая сложность — O(U), тогда как у RNN-T — O(U+T), где U — длина текста, T — длина аудио. Переупорядочивание гипотез в beam почти не требуется. Отдельно подчёркивается, что хоть AED и делает шаги почти так же быстро, как Aligner, благодаря трансформерной природе он сходится за меньшее число итераций.
Илья Новицкий