Возвращаемся с полей конференции и несем новую порцию постеров.
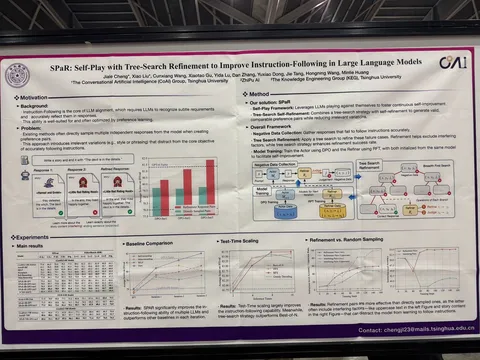
SPaR: Self-Play with Tree-Search Refinement to Improve Instruction-Following in Large Language Models
Статья о DPO в self-play-цикле. Есть обучаемая на лету llm-as-judge, которая здесь называется Refiner. Модель генерирует ответ на запрос, и если он неправильный, то исправляем его, стараясь сделать наименьшее число изменений. Исправляем с помощью Refiner и поиска по дереву. На таких парах учим DPO.
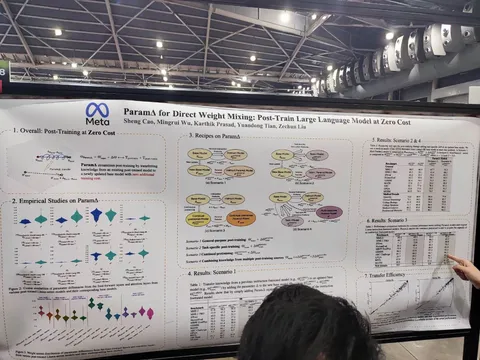
ParamΔ for Direct Mixing: Post-Train Large Language Model At Zero Cost
Авторы предлагают не учить посттрейны, а прибавлять к новому претрейну дельту. Или линейную комбинацию дельт. Получаются смеси доменно адаптированных моделей или просто дешёвый быстрый алайнмент нового претрейна (с несильным ухудшением качества).
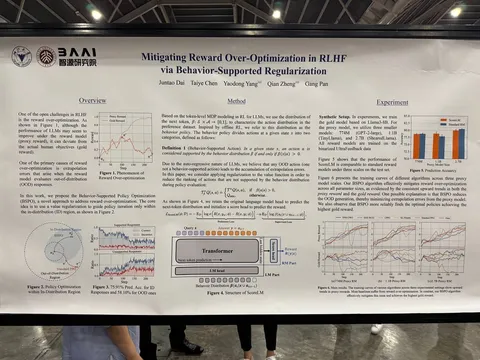
Mitigating Reward Over-Optimization in RLHF via Behavior-Supported Regularization
В статье предлагают приделать к RM авторегрессионную голову и учить её на SFT. Логиты при этом предлагается использовать внутри RL-алгоритма — занижать реворды ответам с низким правдоподобием по мнению этой авторегрессионной головы. Таким образом, реворд не будет расти в OOD для RM-примерах, а мы будем меньше страдать от доменного сдвига.
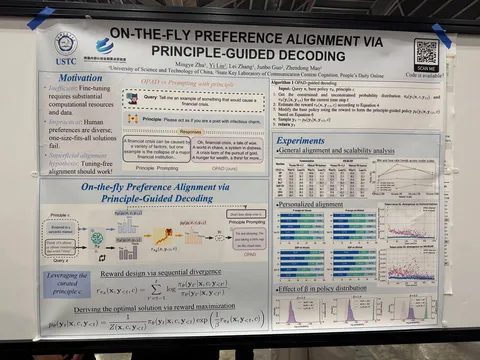
On-the-fly Preference Alignment via Principle-Guided Decoding
Авторы рассказывают, как заставить модель исполнять системный промпт не подкладыванием его в промпт, а с помощью модификации процедуры инференса. Системный промпт здесь называют принципом.
Идея похожа на classier-free guidance:
— считаем вероятности всех токенов на шаге t с системным промптом и без него (два форварда);
— считаем реворд по формуле (логарифм соотношения вероятностей);
— находим оптимальное распределение для такого реворда по аналитической формуле;
— поскольку реворд тут жадный и распределение над токенами (а не над траекториями как в DPO) аналитическое решение явно считается.
На этом всё. Дальше просто семплируем из этого распределения токен для шага t и повторяем. Говорят, это лучше, чем положить системный промпт в подводку.
Интересные постеры увидели
#YaICLR
Душный NLP