Крупнейшая ML-конференция проходит сразу в двух местах: в Сан-Диего и Мехико. Руководитель группы AI-планирования робота доставки Дмитрий Быков находится в Мексике и делится с нами тем интересным, что видит на мероприятии. Слово Дмитрию.
State Entropy Regularization for Robust Reinforcement Learning
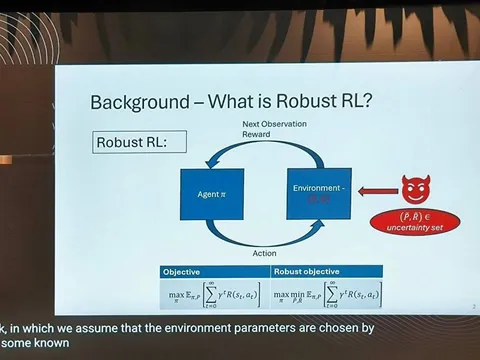
Статья о том, как сделать RL устойчивым. Под устойчивостью понимается, что модель корректно работает в худших кейсах, когда награды или переходы оказываются не такими, как при обучении.
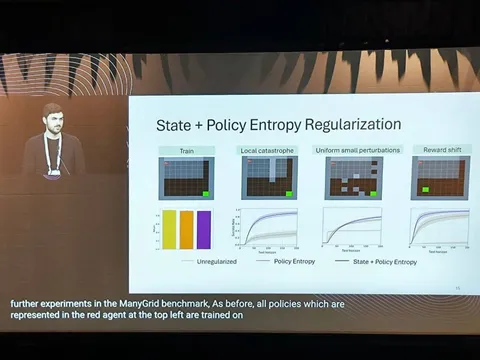
Авторы утверждают, что регуляризация энтропии политики (policy entropy) приводит к тому, что весь эксплорейшен сосредоточен вокруг оптимальной траектории. Поэтому, выходя за её пределы, модель оказывается в незнакомой для себя ситуации. Регуляризация энтропии стэйта (state entropy), в свою очередь, вознаграждает агента за то, что он проходит по тем состояниям, в которых не был.
В статье предлагают использовать регуляризации обеих энтропий, чтобы учиться быть устойчивыми и к большим, и маленьким изменениям. При этом я не заметил сравнения вариантов отдельных регуляризаций против двух вместе.
Больше интересного с NeurIPS ищите в наших каналах ML Underhood, 404 Driver Not Found и CV Time по хештегу #YaNeurIPS25.
Душный NLP