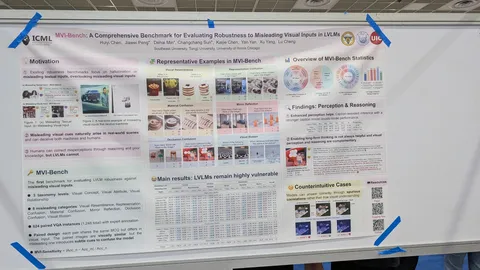
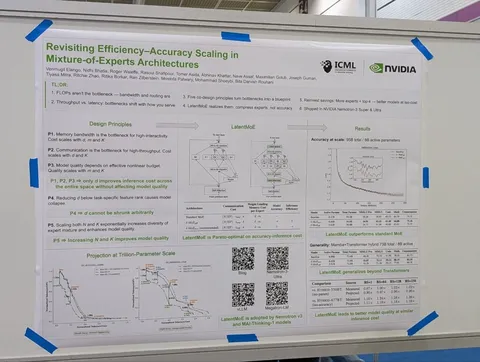
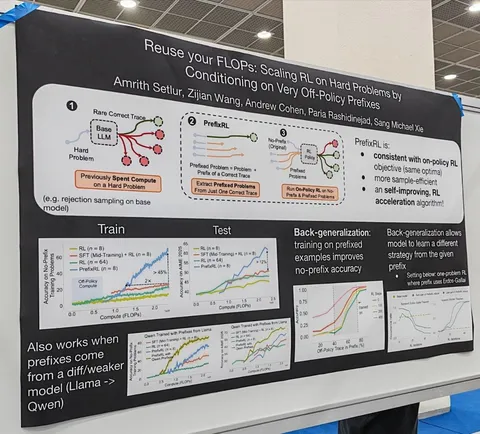
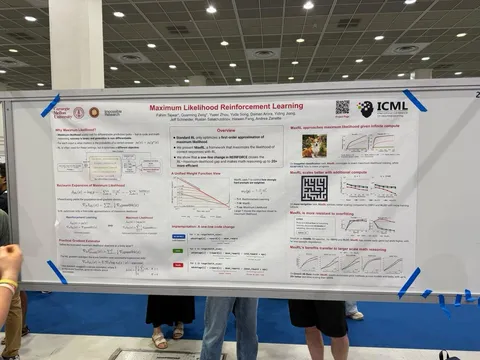
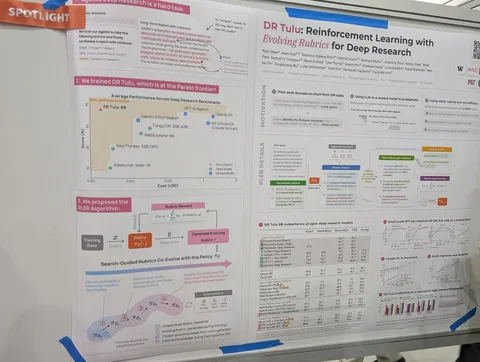
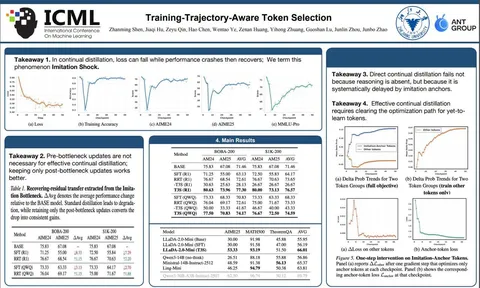
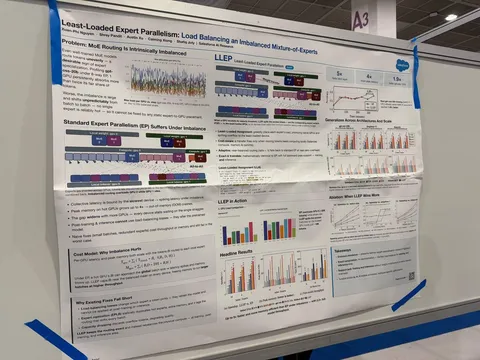
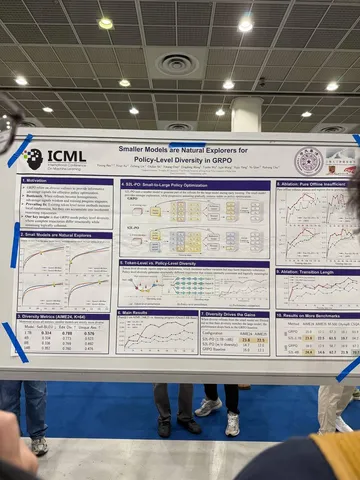
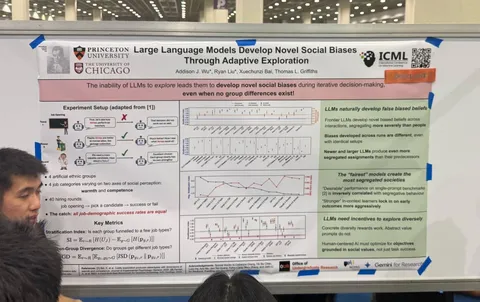
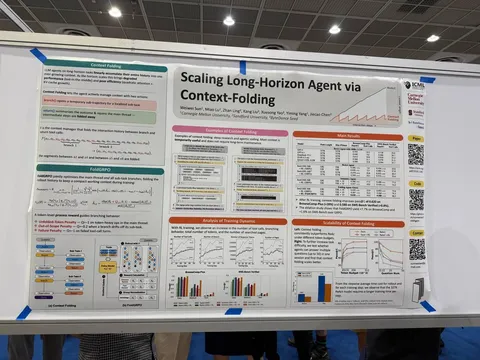
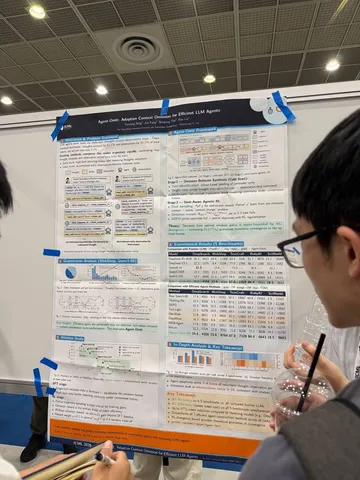
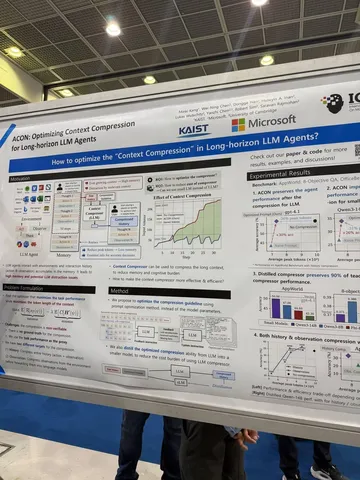
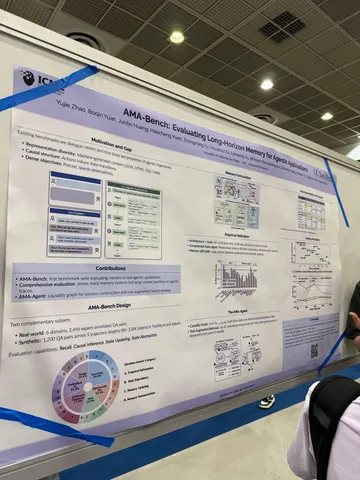
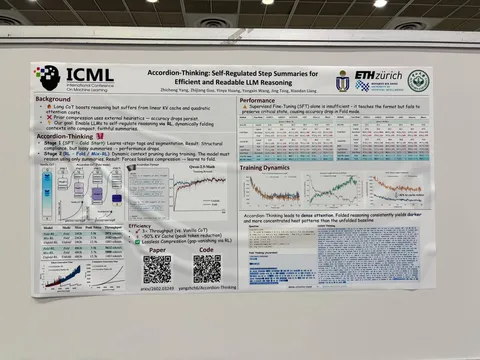
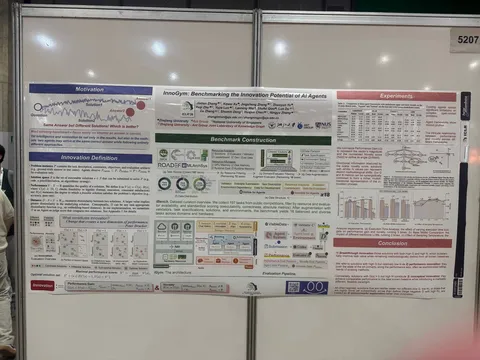
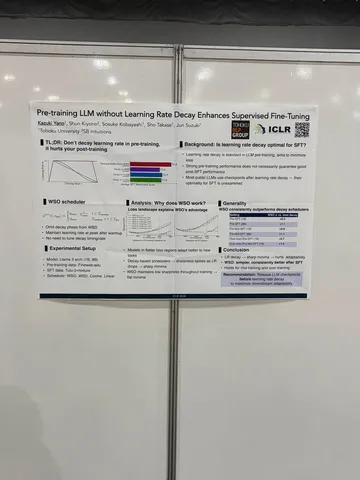
Asynchronous Reasoning: Training-Free Interactive Thinking LLMs
Сегодня поговорим о статье, в написании которой принимали участие инженеры Яндекса. Публикация посвящена асинхронному ризонингу, а в её основе лежит метод, описанный в работе Hogwild! Inference: Parallel LLM Generation via Concurrent Attention, поэтому сперва — кратко о ней.
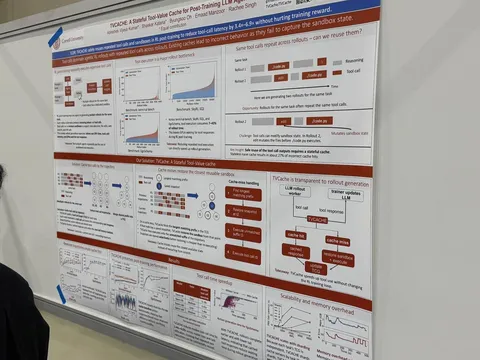
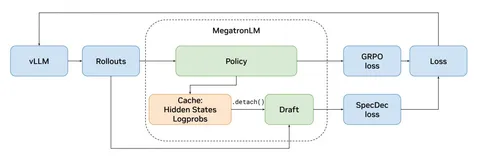
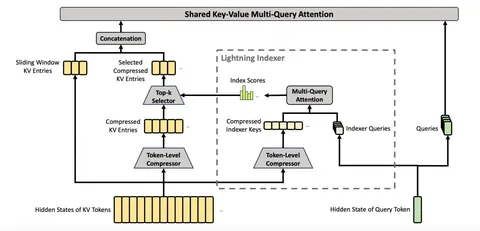
Это тоже статья от Yandex Research, а также от HSE и IST Austria. Авторы поставили перед собой задачу ускорить инференс с помощью параллельной генерации. Для этого ввели понятие Cash Blocks. Есть блок common cash, где находится общий промпт (например, решить какое-либо уравнение), и есть блоки «рабочих» (workers) — других потоков генерации той же LLM, которые выполняют задачу, синхронизируясь через KV-кэш. В статье эти блоки называются Алиса и Боб.
Для генерации токена Алисы нужно, чтобы блоки стояли в порядке common-Bob-Alice, а для Боба — common-Alice-Bob. Так каждый «рабочий» может генерировать свои токены, «видя» чужие генерации, и они могут в реальном времени общаться между собой. Для генерации нового токена блоки KV-кэша упорядочиваются по-разному для каждого «рабочего». Сдвиг осуществляется не над всем блоком, а над query-токенами, что снижает вычислительные издержки. Это суть метода, а подробнее о Hogwild! мы писали в этом посте.
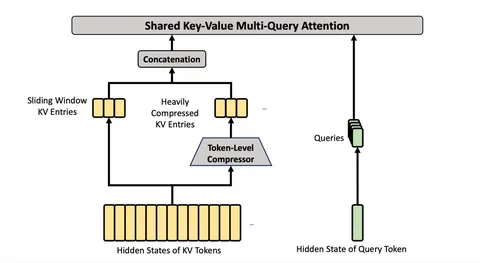
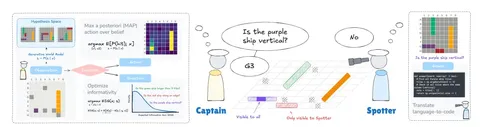
Идея асинхронного ризонинга немного иная. В Hogwild! разбивали большую цепочку ризонинга на параллельные фрагменты для обработки двумя «рабочими», чтобы добиться некоторого ускорения. При этом Алиса и Боб — почти симметричны, лишь немного отличаются промптами. Однако сами кэш-блоки в теории могут отличаться: один, например, может быть обёрнут в ризонинг-токены, а другой нет. Также не обязательно генерировать по одному токену для каждого «рабочего» за форвард, как это сделано в Hogwild! Из этих предпосылок и рождается идея AsyncReasoning.
Суть такова: есть также два потока одной LLM — writer и thinker. Первый генерирует выходные токены, а второй — ризонинг-токены. Благодаря этому появляется возможность генерировать ответ раньше, чем завершился ризонинг. С точки зрения thinker, токены writer — это предыдущий шаг генерации, а writer «живёт» в рамках одной непрерывной генерации.
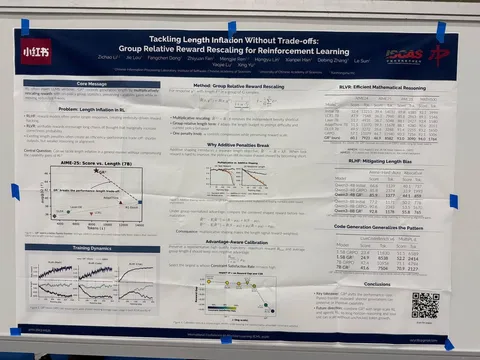
Чтобы сделать этот сетап более интерактивным, — скажем, в случаях, когда thinker надо подольше подумать — используют переключение режимов (mode switching). По сути, это отдельный view, от которого модели задаётся вопрос «Достаточно ли моих текущих измышлений, чтобы написать следующий параграф или формулу?» (Wait, are my current thoughts enough to write the next paragraph or formula?) В зависимости от ответа — да или нет — writer либо включается, либо ждёт дальше. Вопрос задаётся каждые 20 шагов.
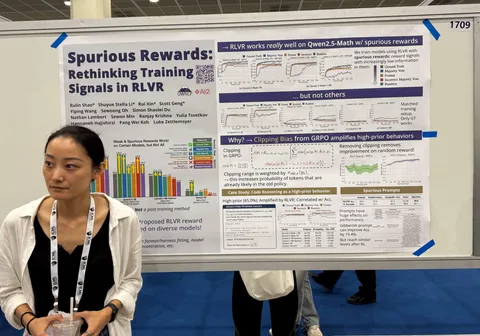
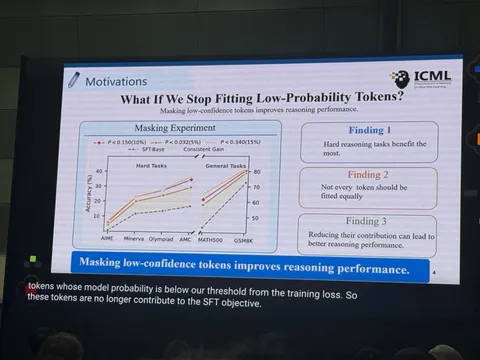
Замеры в основном проводились на математических датасетах. Кроме того, замеряли delay — суммарную длительность пауз, которые происходят при переводе ответа модели в звук. Благодаря mode switching writer генерирует токены не на каждом форварде, а перевод ответа в звуковое представление позволяет лучше зафиксировать те самые паузы между генерациями. Также измерялось time to first token. Как показали эксперименты, ещё AsyncReasoning помогает повысить безопасность модели.
Разбор подготовил❣ Георгий Якушев
Душный NLP
Сегодня поговорим о статье, в написании которой принимали участие инженеры Яндекса. Публикация посвящена асинхронному ризонингу, а в её основе лежит метод, описанный в работе Hogwild! Inference: Parallel LLM Generation via Concurrent Attention, поэтому сперва — кратко о ней.
Это тоже статья от Yandex Research, а также от HSE и IST Austria. Авторы поставили перед собой задачу ускорить инференс с помощью параллельной генерации. Для этого ввели понятие Cash Blocks. Есть блок common cash, где находится общий промпт (например, решить какое-либо уравнение), и есть блоки «рабочих» (workers) — других потоков генерации той же LLM, которые выполняют задачу, синхронизируясь через KV-кэш. В статье эти блоки называются Алиса и Боб.
Для генерации токена Алисы нужно, чтобы блоки стояли в порядке common-Bob-Alice, а для Боба — common-Alice-Bob. Так каждый «рабочий» может генерировать свои токены, «видя» чужие генерации, и они могут в реальном времени общаться между собой. Для генерации нового токена блоки KV-кэша упорядочиваются по-разному для каждого «рабочего». Сдвиг осуществляется не над всем блоком, а над query-токенами, что снижает вычислительные издержки. Это суть метода, а подробнее о Hogwild! мы писали в этом посте.
Идея асинхронного ризонинга немного иная. В Hogwild! разбивали большую цепочку ризонинга на параллельные фрагменты для обработки двумя «рабочими», чтобы добиться некоторого ускорения. При этом Алиса и Боб — почти симметричны, лишь немного отличаются промптами. Однако сами кэш-блоки в теории могут отличаться: один, например, может быть обёрнут в ризонинг-токены, а другой нет. Также не обязательно генерировать по одному токену для каждого «рабочего» за форвард, как это сделано в Hogwild! Из этих предпосылок и рождается идея AsyncReasoning.
Суть такова: есть также два потока одной LLM — writer и thinker. Первый генерирует выходные токены, а второй — ризонинг-токены. Благодаря этому появляется возможность генерировать ответ раньше, чем завершился ризонинг. С точки зрения thinker, токены writer — это предыдущий шаг генерации, а writer «живёт» в рамках одной непрерывной генерации.
Чтобы сделать этот сетап более интерактивным, — скажем, в случаях, когда thinker надо подольше подумать — используют переключение режимов (mode switching). По сути, это отдельный view, от которого модели задаётся вопрос «Достаточно ли моих текущих измышлений, чтобы написать следующий параграф или формулу?» (Wait, are my current thoughts enough to write the next paragraph or formula?) В зависимости от ответа — да или нет — writer либо включается, либо ждёт дальше. Вопрос задаётся каждые 20 шагов.
Замеры в основном проводились на математических датасетах. Кроме того, замеряли delay — суммарную длительность пауз, которые происходят при переводе ответа модели в звук. Благодаря mode switching writer генерирует токены не на каждом форварде, а перевод ответа в звуковое представление позволяет лучше зафиксировать те самые паузы между генерациями. Также измерялось time to first token. Как показали эксперименты, ещё AsyncReasoning помогает повысить безопасность модели.
Разбор подготовил
Душный NLP
1 083 просмотров · 14 реакций
Открыть в Telegram · Открыть пост на сайте