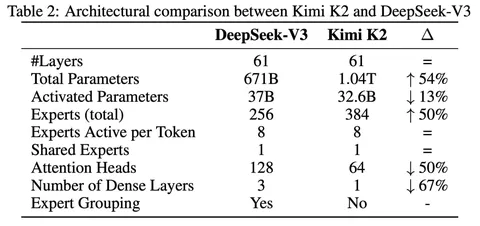
Сегодня разберём статью о MoE-модели Kimi K2 на триллион параметров. У Kimi в полтора раза больше экспертов, чем у DeepSeek-V3 — 384 против 256. А ещё — в два раза меньше голов аттеншена — 64 против 128.
Создатели вводят понятие sparsity — это разница между общим количеством экспертов и активными экспертами. Так, у Kimi K2 sparsity 48, а у DeepSeek-V3 — 36. Авторы утверждают, что при увеличении sparsity улучшается validation loss модели, но и растёт её инфраструктурная сложность. Что касается небольшого, по сравнению с DeepSeek, числа голов аттеншена, то это решение связано с тем, что удвоение голов даёт прибавку к validation loss всего в 1,2% и кажется нецелесообразным.
На претрейне Kimi K2 использовался собственный алгоритм Muon, включающий в себя быстрое преобразование к ортогональной матрице. Однако при применении этого метода происходит «взрыв» логитов аттеншена. Чтобы справиться с этой проблемой, авторы устанавливают максимальные логиты для каждой головы. Дальше, всё, что больше заданного T, клипают. Следом идёт рескейлинг матриц W_k и W_q с gamma_h = min(1 или T/на максимальный логит). В случае с обычным MHA все это домножается на гамму, а в случае с MLA скейлятся только не пошаренные веса голов аттеншена.
Также на претрейне авторы перефразировали данные с помощью промптов — то есть буквально переписывали их, сохраняя семантическое родство. Большие тексты разбивались на отдельные фрагменты, которые затем переписывались и подавались в качестве контекста для следующего фрагмента. После десяти перефразирований и одной эпохи прибавка на SimpleQA получается более чем в пять пунктов по сравнению с использованием «оригинального» текста в течение 10 эпох.
На пострейне использовали 3000 MCP тулов с GitHub и ещё 10 тысяч — синтетических инструментов. По тулам сгенерировали тысячи агентов. Они получили сгенерированные задачи, оценкой которых происходила в режиме LLM-as-a-Judge. Успешные траектории становились базой для обучения.
На этапе RL для случая, когда нет верифицируемой награды, модель использовали одновременно и как актора, и как критика. Актор генерировал набор ответов, которые критик попарно сравнивал относительно набора аспектов. Сам критик обновлялся за счёт verifiable-сигналов.
Разбор подготовил
Душный NLP