Влияют ли математические рассуждения (reasoning) на другие домены при обучении модели? Короткий ответ — да, влияют. А для тех, кому интересны подробности, сегодня разберём статью об этом.
Для рассуждений все небезуспешно максимизируют математику благодаря формализованной постановке задач и относительно лёгкой (по сравнению с другими доменами) верификации решений. Звучит здорово, но мир не ограничивается math reasoning: обучая LLM математике, учим ли мы её рассуждать в целом? Можно ли масштабировать успехи в одном домене на другие области?
Чтобы ответить на эти вопросы, авторы:
— Создали метрику transferability index (или просто TI), которая позволяет оценить, как переносятся рассуждения между различными доменами.
— Собрали датасет из 40K математических задач с незатейливым названием Math 40K. Источники данных: DeepScaleR с олимпиадной математикой и Simple LR сложностью от 3 до 5 — математика старшей школы и выпускных экзаменов.
— Обучили Qwen3-14B-Base в двух парадигмах: SFT и RL (с выравниванием длины обучения). В RL использовали классический GRPO без KL-дивергенции и штрафов по энтропии. В качестве данных для SFT применили ответы модели Qwen3-32B с rejection samling.
— Измерили бенчмарки других доменов и оценили эффект от разных подходов к обучению.
— Проанализировали результаты, активации моделей и выходные распределения токенов, пришли к следующим выводам: да, обучение рассуждениям в области математики влияет на рассуждения в других доменах; но на SFT модель переобучается под математический домен, а RL позволяет переносить полученные принципы на другие области. Выводы подкрепили анализом 20 современных open-weight-моделей с хорошей математикой.
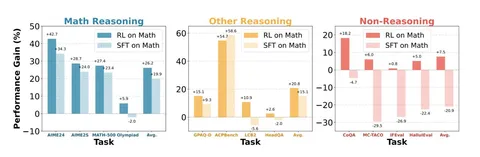
На диаграммах выше — собранные в три группы доменов оценки того, как SFT и RL на математических данных влияют на способности модели к рассуждению. Легко заметить, что RL показывает наилучшие результаты на всех бенчах, кроме ACPBench. Плохие результаты SFT для non-reasoning могут сигнализировать о том, что модель переобучается математике.
Transferability index (TI) вычисляется следующим образом: сначала для каждой группы бенчмарков (math, other reasoning, non-reasoning) считается средний относительный прирост: dR = SUM((R_model – R_base) / R_base) / N, где R_model — результат экспериментальной модели после обучения, R_base — результат бейзлайна до обучения, N — число бенчмарков в группе. Отношение dR other reasoning или non-resoning к math и есть искомая метрика TI. Когда её величина больше единицы, другие группы растут вместе с математикой, обучение улучшает качество работы модели на других доменах. А вот если TI < 1, обучение математике ведёт к ухудшению качества работы модели по другим тематикам.
Посчитав TI для множества опенсорс-моделей, авторы пришли к выводу: обучение на математических данных с помощью RL позволяет переносить способности к рассуждению на другие домены, а SFT не демонстрирует такого эффекта. Таким образом, математический reasoning влияет на другие домены при обучении модели.
Разбор подготовил
Душный NLP