В Сучжоу в эти дни проходит конференция Conference on Empirical Methods in Natural Language Processing, а мы, как и прежде, рассказываем, об интересных постерах, которые там увидели.
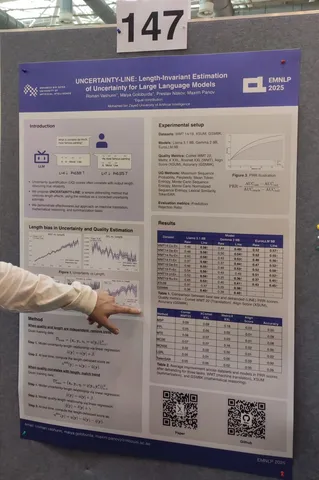
UNCERTAINTY-LINE: Length-Invariant Estimation of Uncertainty for Large Language Models
Очень простая идея, но при этом, кажется, вполне полезная. Странно, что такого никто не делал.
Хотим оценить качество ответа модели на запрос с помощью того, насколько она уверена в том, что пишет. Считаем uncertainty — неуверенность модели в предсказании — как нам нравится (можно перплексию, можно вероятность всего текста, как произведение вероятностей токенов). Получаем величину, которая может зависеть от длины ответа. Утверждается, что это плохое качество метрики, так как у ответов разной длины может быть разное качество.
Авторы строят зависимость uncertainty от длины ответа, аппроксимируют прямой и вычитают полученный линейный тренд из всех значений. Утверждают, что теперь скорректированная uncertainty-метрика лучше коррелирует с качеством ответа. Тестирование проводилось на заданиях WMT (машинный перевод), XSUM (суммаризация), GSM8k (математика, оценивали длину рассуждений). Корреляция тут sample-wise, то есть примеры в бенче ранжируются друг относительно друга правильно.
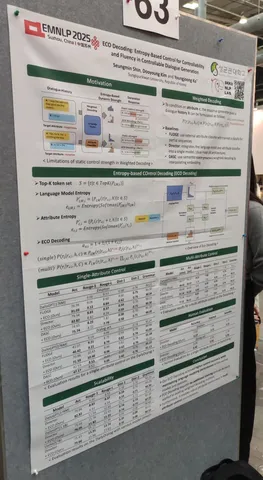
ECO Decoding: Entropy-Based Control for Controllability and Fluency in Controllable Dialogue Generation
Авторы рассматривают controllable-диалоги с LLM, то есть такие, в которых пользователь задаёт вопрос, а ответить нужно с определённым ограничением: радостно, с удивлением и так далее. Есть LLM, которая отвечает за генерацию ответа, но рядом сидит ещё и классификатор, который определяет ограничение и изменяет распределение вероятностей выходных токенов при генерации, чтобы оно лучше подходило под ограничение.
Существуют разные способы этого влияния классификатора на распределение выходных токенов. Авторы придумали свой, назвали его ECO. Утверждают, что качество выросло на некоторых бенчмарках, при этом без потерь в грамматике.
C3: A Bilingual Benchmark for Spoken Dialogue Models Exploring Challenges in Complex Conversations
Авторы собрали датасет из голосовых фраз и диалогов, в которых что-то неоднозначно: интонация (из-за чего непонятно, это вопрос или утверждение), двусмысленность (Mr. Smith loves music more than his wife — «больше, чем его жена любит музыку» или «больше, чем свою жену»?), пропуски слов и так далее. Датасет на английском и китайском, примеры независимые, так как сложно повторить одно и то же на разных языках. Метрика — процент правильно угаданных смыслов. Из всех опробованных авторами моделей лучше всего себя показывает GPT-4o Audio.
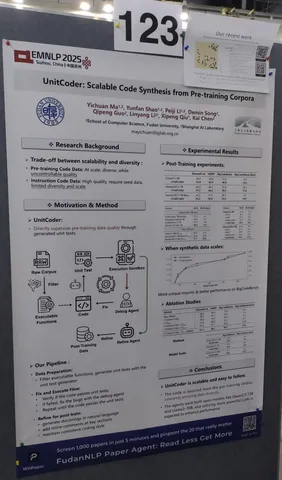
UnitCoder: Scalable Iterative Code Synthesis with Unit Test Guidance
Авторы хотят обучить модель на коде. Есть два стула: либо супергрязный, но при этом большой разнообразный датасет из данных, которые просто выгрузили отовсюду; либо написать хорошие данные с помощью людей или умных моделей, — но это менее разнообразно, и получается не очень много данных.
Авторы захотели сесть между двух стульев и придумали следующий пайплайн генерации данных. Берём просто сырой код из большого разнообразного датасета. Далее вытаскиваем из кодовых документов отделяемые куски кода, которые можно независимо вызывать. Затем на вызываемую функцию пишем тесты с помощью Llama3-70B-Instruct, запускаем тесты этого куска кода в специальной среде, если тесты не проходятся, фиксим код с помощью той же Llama 70B и повторяем пайплайн.
Когда всё стало хорошо, подчищаем код: пишем docstring, вставляем inline-комментарии, улучшаем стиль. В итоге — хороший датасет.
Проблема в том, что тесты пишет и код исправляет умная большая модель, а датасет используется для обучения маленьких (до 7B). По сути, это дистилляция. Автор говорит, что, наверное, достаточно умная Qwen3 сможет сама учиться на своих данных — звучит сомнительно, так что применимость работы к большим моделям под вопросом. Тем не менее идея может быть полезна как ещё один способ дистилляции кодовых навыков.
Интересное увидел
Душный NLP