Возвращаемся с очередной пачкой постеров, которые привлекли внимание нашей команды на конференции.
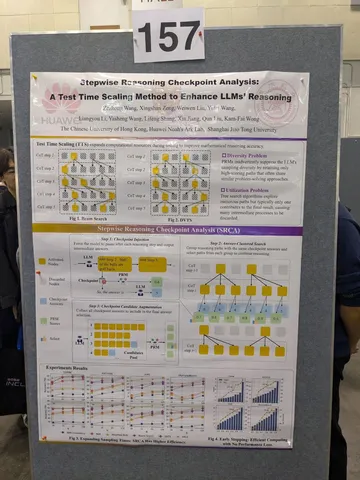
Stepwise Reasoning Checkpoint Analysis: A Test Time Scaling Method to Enhance LLMs' Reasoning
Хорошо известно, что качество обученных LLM на инференсе улучшается с помощью Chain-of-Thoughts (CoT). Можно пойти ещё дальше и делать многостадийный CoT, применяя при этом beam search или DVTS. Но тут могут возникать очень похожие траектории, а также существует риск игнорирования моделью промежуточных шагов.
Для решения этих проблем авторы предлагают метод SRCA, который состоит из двух шагов:
1. заставляем модель после каждого шага выдавать промежуточный результат;
2. группируем результаты в кластеры и стартуем следующий шаг из разных кластеров.
Далее результаты со всех шагов агрегируются в финальный результат.
Liaozhai through the Looking-Glass: On Paratextual Explicitation of Culture-Bound Terms in Machine Translation
В статье рассматривается проблема перевода слов или выражений, культурно-специфичных для исходного языка и не существующих на языке перевода. В профессиональном переводе для них часто применяют метод эксплиситации — замены прямого перевода на описательную конструкцию в скобках или в примечании.
Современные MT-модели (в том числе и LLM) переводят большинство таких фраз буквально или копированием, делая результат непонятным. В статье вводят новую задачу перевода с объяснением и предлагают датасет для оценки качества — выделенные культурно-специфичные выражения и референсные сноски от переводчиков. Сегодняшние LLM плохо справляются с выделением терминов для эксплиситации, но генерируют довольно качественные описания (хоть и хуже переводческих).
Too Consistent to Detect: A Study of Self-Consistent Errors in LLMs
Существующие методы unsupervised-детекции ошибок LLM в большинстве основаны на «мерах разброса» — неопределенности вероятностного распределения, различиях среди diverse-генераций и оценке вероятности модели.
Авторы рассматривают ошибки в ответах LLM и вводят понятие self-consistent-ошибок, уверенных с согласованными предсказаниями. Такие ошибки плохо распознаются мерами разброса. Вместе с тем при скейлинге модели их количество растет, а число inconsistent ошибок, наоборот, сильно снижается.
Предлагается использовать пару разных моделей для детекции self-consistent-ошибок. Метрика на основе модели-верификатора принимает на вход активации двух моделей и использует их линейную комбинацию для предсказания QE-метрики. Такая схема распознает намного больше self-consistent-ошибок в небольших версиях Qwen и Llama.
Интересное увидели
Душный NLP