Авторы сегодняшней статьи рассматривают проблему, из-за которой модель, давая правильный ответ на вопрос, ошибается в рассуждениях. Это случается, например, в ходе решения задач по математическому анализу, где ответ часто — 1, 0, e или pi. Модель может попросту угадать правильный результат, ошибившись в процессе решения.
Для того чтобы модель справлялась с математическими задачами, хорошо подходит process reward modeling (PRM). Это реворд-модель, которая проверяет не окончательный ответ, а каждый шаг решения, что позволяет раньше обнаруживать ошибку в рассуждениях и, соответственно, получать более точные результаты. Однако обучение PRM требует разметки людьми, что дорого.
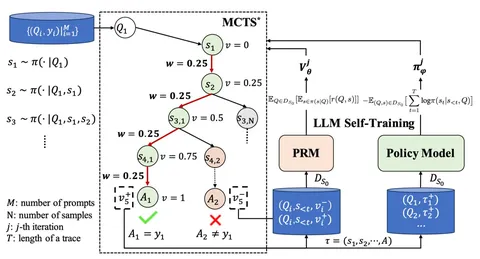
В публикации предлагается использовать Monte Carlo Tree Search (MCTS), чтобы одновременно учить policy и PRM. Идея в том, чтобы превратить рассуждение в дерево поиска: каждый узел — это промежуточное решение задачи, а ребро — следующий шаг. MCTS с текущей policy генерирует продолжения, обходит дерево и старается тратить больше вычислений там, где выше шанс прийти к правильному ответу. Перспективность каждого следующего шага оценивает обученная PRM.
Придуманный авторами алгоритм ReST-MCTS*, предполагает расчёт инкрементального реворда для частичных решений V_k, который меняется от 0 до max_V (всегда положительное значение). Пустой префикс имеет V_0 = 0, а max_V достигается на завершенном правильном решении. В правильном решении каждый шаг добавляет одинаковый инкремент в V_k:
V_k+1 = V_k + (1-V_k)/(m_k+1)*(1-2*r_sk)
Здесь m_k — количество шагов до конца решения, а r_sk — признак качества шага (0 — для правильного ответа, 1 — для неправильного). Если шаг корректный, множитель (1-2*r_sk) равен 1, а V_k плавно растёт и к последнему шагу доходит до max_V; если в какой-то момент совершается ошибка, множитель становится -1, инкремент меняет знак, и значение начинает уменьшаться.
Когда поиск заканчивается, дерево «превращается» в обучающие данные. Из него берут решения, которые приводят к правильному ответу (это можно проверить по совпадению с эталоном или с помощью отдельного LLM-as-a-Judge). Эти решения используют для SFT-дообучения policy. Все узлы, через которые проходят корректные ветки, автоматически получают целевые значения v — их можно трактовать как псевдоразметку качества шага и использовать для обучения PRM, снова без участия людей.
Дальше цикл повторяется: обновлённые policy и PRM запускаются на новых задачах, строят уже более «умные» деревья, генерируют более правдоподобные решения и оценки V, которые снова идут в обучение.
Разбор подготовил
Душный NLP