Сегодня разберём оценку реворд-моделей (RM). Стандартная метрика в этой сфере — accuracy на парах предпочтений из тест-сета. Оценка реворд-моделей нужна как прокси для end-to-end (e2e) RLHF, потому что для каждого эксперимента обучать модель по реворду — это слишком дорого. К тому же качество e2e не всегда связано напрямую с качеством RM из-за большого количества параметров RLHF-обучения.
В экспериментах с RM нередко применяют синтетический сетап: вместо истинной награды (которую в реальном мире обычно дают люди) используют «сильную» RM. Её предсказания принимают за Golden Reward, а в рамках экспериментов обучают Proxy RM, которые максимально приближают Golden — это существенно снижает стоимость исследований.
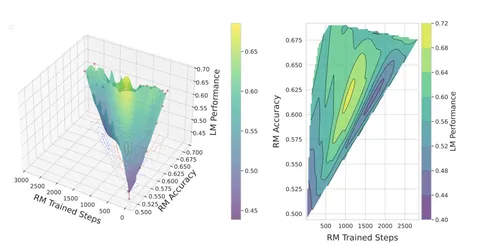
Одна из работ на тему оценки RM — The Accuracy Paradox in RLHF, авторы которой обучили отдельные реворд-модели (Longformer-base-4096) на одну из трёх задач: релевантность, полнота и фактологичность, таргеты которых собирались через Golden RM. Дальше под каждую модель обучали RLHF и смотрели на конечное качество. Выяснилось, что максимальное значение accuracy RM не обязательно ведёт к высокому е2е-качеству во всех трёх задачах. На первом графике видно, что оптимальное качество (жёлтый цвет) соответствует среднему значению accuracy.
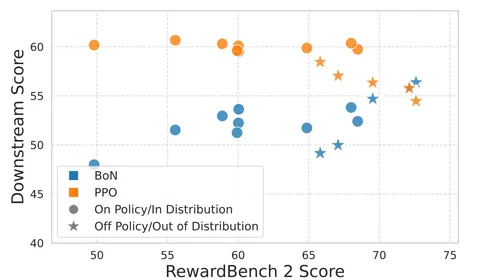
Для проверки RM используют бенчмарки — например, RewardBench 2. В нём шесть доменов, включая математику, следование инструкциям, безопасность, фактологичность и так далее. Для сравнения на каждый промпт предоставляется один правильный и три неправильных ответа (best-of-4 accuracy).
Эксперименты создателей RewardBench 2 показали, что, вопреки распространённому мнению, RM имеет смысл обучать больше одной эпохи — это даёт рост в качестве. Кроме того, разработчики бенчмарка заключают, что качество растёт, если RM и Policy из одного семейства — например, Llama. А вот чего делать не стоит, так это использовать в RLHF промпты, которые не «видела» реворд-модель (звёзды на изображении 2).
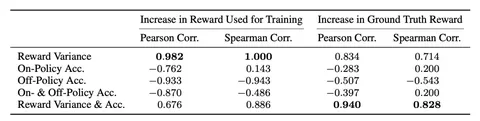
Авторы статьи What Makes a Reward Model a Good Teacher? An Optimization Perspective предлагают смотреть не только на accuracy, но и на дисперсию реворда. Чем она выше, тем быстрее модель оптимизируется под gold reward — то есть, эталонную оценку (изображение 3). Вывод опять-таки следующий: высокая accuracy не ведёт к высокому е2е-качеству.
Разбор подготовил
Душный NLP