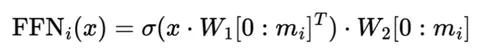Сегодня расскажем о методе, который позволяет обучить одну модель, а затем извлечь из неё несколько других «подмоделей». Подобным подходам посвящено несколько статей. Разберём одну из них, о методе MatFormer от инженеров из Google.
Идея статьи заключается в том, чтобы вкладывать разные варианты слоёв друг в друга. Как в матрёшке: параметры трансформера поменьше используются в трансформере побольше. Метод фокусируется на FFN-слоях и только в dense-архитектурах, где до 60% параметров как раз и находятся в FFN-слоях.
Суть в том, чтобы брать не все нейроны скрытого слоя в полносвязных слоях, а а только некоторый набор первых (m_i в формуле выше). При этом у разных слоёв могут быть разные m_i.
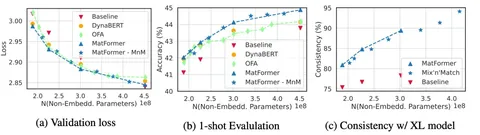
Обучение осуществляется как обычно, но со случайным и равномерным сэмплингом m_i = g_i d_ff, где g_i — гранулярность, случайно сэмплируемая из {0.5, 1, 2, 4}, а d_ff — это размер скрытого представления модели. Таким образом обучаются все подмодели. На инференсе используется процедура Mix’n’Match — для разных слоёв подбираются свои m_i так, чтобы размер слоёв увеличивался постепенно, без резких скачков.
Результаты показывают, что модель, полученная с помощью метода MatFormer, показывает лучшие результаты, чем модель, обученная с нуля. Интересно ещё и то, что «модели из матрёшки» демонстрируют значительную согласованность с большой моделью, из которой произошли. Это полезно, потому что открывает возможность для использования маленьких моделей, например, в качестве draft-моделей при спекулятивном декодинге.
Разбор подготовил
Душный NLP