Конференция ICLR 2025 закончилась давным-давно, но она навсегда в наших сердечках — так много интересного там было. Делимся ещё одной — запоздавшей, но от этого не менее любопытной — подборкой статей с мероприятия.
OstQuant: Refining Large Language Model Quantization with Orthogonal and Scaling Transformations for Better Distribution Fitting
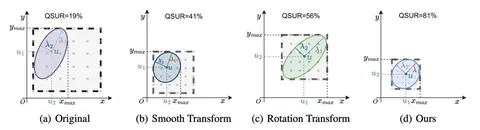
Авторы вводят метрику утилизации пространства квантизации. Для наглядности посмотрите на изображение. Есть некоторый объём, который фактически занимает тензор, и тот объём, который может представлять собой квантизованные значения — красный квадрат на картинке. Если эти два объёма смещены относительно друг друга и не полностью совпадают, то имеет место ошибка. В идеале, если сильно упрощать, распределение тензора должно быть чётко вписано в квадрат объёма квантизации.
На практике этого можно добиваться разными способами вроде Rotation или Smooth. Авторы статьи предлагают при нормализации весов добавить к вращению операцию Smooth. На инференсе всё это ужимается в одну матрицу. Таким образом, можно получить прирост по качеству на 1 п.п. при использовании SpinQuant.
Block Verification Accelerates Speculative Decoding
При сэмплинге мы сэмлируем случайную величину от нуля до единицы из равномерного распределения и сравниваем её с вероятностью принятия. В теории любой токен может оказаться принятым. Авторы статьи предлагают в сэмплинге делать не потокенную верификацию, а поблочную — увеличивать вероятность принятия за счёт того, что на верификацию поступает больший объём информации (изображение 2). Этот метод работает, обеспечивая ускорение в 5–10%.
Antidistillation Sampling
Авторы предлагают настройку, призванную защитить модели от несанкционированной дистилляции. Метод представляет собой добавку к распределению в генерации. В основе — расчёт такой оценки градиентов, которая позволит ухудшить качество дистилляции. Получить эту оценку можно в SFT, с помощью реворд-модели или как-то иначе. Метод реализуется через небольшие сдвиги в логитах — они вычисляются с помощью прокси-модели и аппроксимированного градиента. Это ухудшает обучение «студента» при дистилляции, но почти не снижает эффективность «учителя».
TAID
Хак, призванный решить проблемы mode averaging и mode collapse при дистилляции. Авторы предлагают делать прогрессивную дистилляцию — переходить от SFT «студента» к дистилляции в учителя. Это позволяет сделать распределение более разнообразным. Метод даёт не слишком большой прирост по бенчмаркам, но и реализуется совсем не сложно — нужно добавить всего один параметр на смесь логитов «учителя» и «студента».
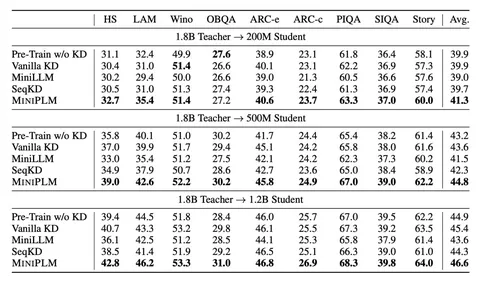
MiniPLM
Распределения «учителя» и «студента» можно классифицировать по трём типам:
— «шумные» — высокая уверенность логитов «студента» и низкая у «учителя»;
— «простые» — логиты «студента» сильно приближаются к логитам «учителя»;
— «сложные» — высокая уверенность «учителя», низкая у «студента».
Авторы статьи предлагают выбрасывать «шумные» примеры, ап-семплить «сложные» и даун-семплить «простые». То есть это просто работа с датасетом, которая, однако, уже показывает хороший прирост качества после дистилляции (изображение 3).
Разбор подготовил
Душный NLP