Сегодня разберём статью о GazeReward — фреймворке, который интегрирует неявную обратную связь eye-tracking (ET) в модель вознаграждения (RM).
GPT, Llama, Claude, Gemini и другие популярные LLM отлично справляются с самыми разными задачами, но результат их работы не всегда соответствует ожиданиям пользователей. Модели часто донастраивают с помощью Reinforcement Learning with Human Feedback (RLHF), но и этот метод недостаточно хорош для точного моделирования предпочтений.
В GazeReward авторы предлагают учитывать данные о движении и фиксации человеческих глаз (eye-tracking или просто ET) в качестве дополнительного сигнала о том, как пользователи воспринимают информацию.
Для интеграции ET в RM авторы предлагают два подхода:
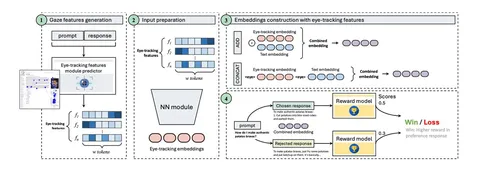
Архитектура фреймворка — на схеме выше. Сначала обучают отдельную модель для предсказания ET и генерируют их фичи. Потом объединяют ET-фичи с текстом, создавая различные типы комбинированных эмбеддингов. В конце — передают в качестве входных данных в RM, которую обучают по стандартной модели Брэдли-Терри.
То есть, традиционный RM с текстовым входом (комбинацией запроса и ответа) дополняют искусственной неявной обратной связью с помощью функций ET, сгенерированных по тому же тексту.
Эксперименты показали: фреймворк GazeReward помог повысить точность прогнозов о предпочтениях людей более чем на 10%. По мнению авторов, это подтверждает потенциал мультимодальных сигналов для NLP.
Разбор подготовил Карим Галлямов
Душный NLP