В последние годы всё больше обсуждают альтернативы классическому аттеншну — прежде всего из-за стоимости квадратичного скейлинга и работы с длинными контекстами. Ниже — краткий обзор нескольких любопытных работ и блогпостов на тему линейного, sparse- и гибридного аттеншна.
Why Did MiniMax M2 End Up as a Full Attention Model?
Начнём с поста от команды MiniMax. Их первая модель, MiniMax M1, была гибридной и использовала простой линейный аттеншн на матричных стейтах. Но во второй версии, MiniMax M2, они неожиданно вернулись к полному квадратичному аттеншну — даже без sliding window attention (SWA), который уже встречается в опенсорсных моделях.
Авторы говорят, что гибридная архитектура у них попросту не заработала. На классических текстовых бенчмарках всё выглядело приемлемо, а вот на агентских задачах — с кодом, итерациями и длинным контекстом — модель стабильно проигрывала. SWA тоже не помог: при дообучении моделей, изначально предобученных с полным аттеншном, ключевые головы не перестраивались и деградировали.
Итоговый вывод у MiniMax осторожный: линейные и гибридные подходы выглядят перспективно, но пока не хватает инфраструктуры, реализаций и бенчмарков. Поэтому на данный момент они остаются со стандартным трансформером и считают, что сначала нужно больше данных и экспериментов с длинным контекстом.
The Sparse Frontier: Sparse Attention Trade-offs in Transformer LLMs
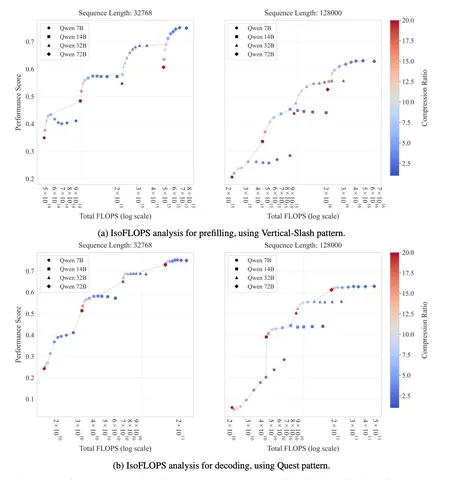
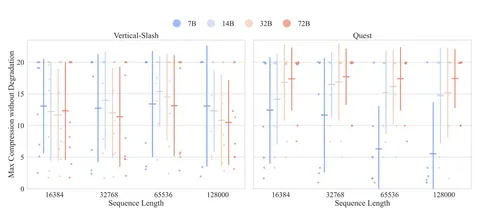
В этой работе изучают training free sparsity в аттеншне и пытаются понять, что реально работает с точки зрения баланса compute/accuracy. На умеренных контекстах спарсификация аттеншна почти не помогает и часто ухудшает качество. На очень длинных — даёт выигрыш по FLOPs, но часто приводит к ухудшению качества: авторы замечают, что метод, работающий на одной задаче, ломается на другой. В среднем удаётся получить около 5× сжатия без сильной деградации качества, но разброс большой, особенно для маленьких моделей.
Evaluating Long Context (Reasoning) Ability
В следующем посте автор критикует популярные long-context-бенчмарки. Он говорит, что needle-in-a-haystack-like-задачи в основном проверяют ретривал и плохо отражают реальную (более сложную) работу с длинным контекстом. На более сложных задачах, где контекст нужно понять, а не просто найти факт (например, в длинном коде с логическими ошибками), модели начинают деградировать уже на десятках тысяч токенов — даже с Full Attention. Вывод: бенчмарков, которые реально проверяют ризонинг на длинном контексте, пока недостаточно.
Kimi Linear: an expressive, efficient attention architecture
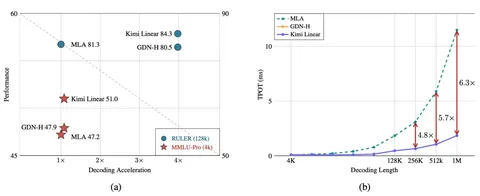
Спустя неделю после скептического поста MiniMax Moonshot AI (авторы модели Kimi K2 и не только) выпустили работу с почти противоположным тезисом: Linear Attention работает. В Kimi Linear предложили Kimi Delta Attention с gated delta rule и рекуррентной матричной памятью. В модели используют соотношение 3:1 линейных слоёв к Full Attention. Качество на бенчмарках в статье не хуже полного аттеншна, а эффективность выше: prefill на длинных промптах быстрее примерно в три раза, декодинг и memory footprint тоже выигрывают за счёт меньшей зависимости от KV-cache.
Разбор подготовил
Душный NLP