Для обучения моделей на длинный контекст требуется много памяти под активации. Cкажем, чтобы обучить Qwen3-235B на контекст в 131 тысячу токенов, только под активации требуется более 100 ГБ, даже при использовании чекпоинтинга. Учитывая, что на карте надо хранить ещё саму модель, состояния оптимизатора и прочее, получается слишком много даже для GPU последних поколений. Что можно с этим сделать?
Большинство операций в трансформере (нормы, mlp, residual) над одним токеном происходят независимо от других. Это значит, что мы можем разбить нашу последовательность на N частей и обрабатывать каждую на отдельной GPU. Но у нас всё ещё остаётся селф-аттеншн, для подсчёта которого необходима вся последовательность. Так мы подходим к группе sequence- и context-parallel-методов вроде TPSP, Ring/ZigZag, Ulysses. Кратко расскажем о последнем.
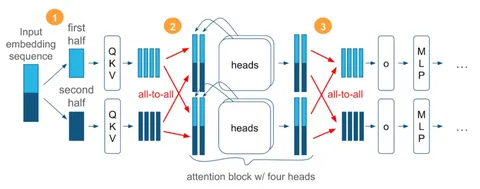
В чём заключается идея:
— каждая GPU внутри context-parallel-группы хранит и обрабатывает только часть последовательности;
— перед тем, как зайти в аттеншн, вычисляем QKV-проекции размера [local_seqlen, global_heads, head_dim];
— делаем all_to_all QKV-проекций и получаем тензор активаций размера [global_seqlen, local_heads, head_dim]. Таким образом, потребление памяти не изменилось, но теперь каждая GPU может вычислять селф-аттеншн независимо, потому что имеет всю последовательность (но только часть голов);
— после вычисления аттеншена и до output-проекции снова делаем all_to_all и снова получаем тензор, разбитый по длине последовательности.
Этот метод обладает серьёзными преимуществами:
— очень прост в реализации, но в то же время может быть эффективным при грамотном перекрытии вычислений и коммуникаций;
— независим от реализации аттеншна и при небольших модификациях работает в том числе с линейными вариантами. Также подходит для мультимодальных сценариев.
Но есть и ограничения. Например, размер CP-группы (Context Parallelism) не может быть больше количества query-голов. В случае GQA требуется копирование KV-голов до размера CP-группы. Кроме того, Ulysses становится довольно дорогим при межхостовых коммуникациях.
Инженеры Яндекса использовали этот метод в Alice AI. Ulysses позволил провести Midtrain-стадию обучения и увеличить контекст с хорошим ускорением за счёт перебалансировки нагрузки между процессами.
Разбор подготовил
Душный NLP