Сегодня разбираем статью от DeepSeek на тему модификации трансформер-архитектуры.
Мотивация
У трансформеров нет native primitive для knowledge lookup, поэтому ретривал им приходится симулировать вычислениями. Идея статьи — добавить в архитектуру явный inductive bias на ретривал через Engram-модуль и улучшить метрики.
Архитектура
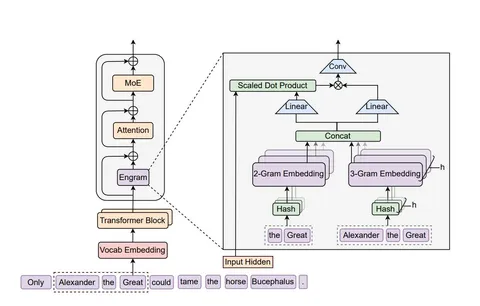
Engram добавляют внутрь блока трансформера, но не во все слои, а максимум в два. Выход модуля добавляется к residual stream. В аблейшенах показали, что лучше всего вставлять Engram-модуль во 2-й слой, а комбинация 2-го и 6-го слоёв даёт более низкий validation loss.
Технически Engram-модуль представляет обучаемые словари nn.Embedding, на вход которых подаются отдельные hash'ы для 2- и 3-грамм. Также в модуле обучаются параметры: context-aware gating (вдохновленный аттеншном), свёртка по seq_len и RMSNorm'ы.
Проверяют модуль в MoE-моделях. В них есть параметры, которые не активны на forward. Allocation ratio (ρ) — это доля неактивных параметров, которая содержится в блоках экспертов; в MoE ρ=1. Параметры для Engram берут, уменьшая количество неактивных экспертов, поэтому становится ρ<1. Чтобы понять, какую долю параметров экспертов оптимально перенаправить в модуль, делают grid search, — запускают несколько претрейнов и меняют только ρ.
Как работает Engram
Работа модуля начинается с обработки входных токенов. Делают tokenizer compression: применяют детерминированные преобразования, чтобы привести токены к canonical ID. Это как стемминг или лемматизация, но для токенов.
Из последовательности токенов строят 2- и 3-граммы. Напрямую индексировать n-граммы нельзя (их слишком много), поэтому используют Hash Embeddings-подход для уменьшения коллизий в рамках небольшого словаря. Для каждой n-граммы получают хеш (вариация multiplicative-XOR), т.е. одно число. Используется несколько голов, поэтому на выходе получается несколько хешей-чисел. Это буквально индексы, по которым получают вектора из nn.Embedding, где у каждой головы и n-граммы независимые вектора — и дальше их конкатенируют.
Дальше — context-aware gating. Берут механизм сродни dot product attention: входной hidden state слоя используется как query, а к эмбеддингам применяют линейные преобразования, аналогичные W_K и W_V. В отличие от аттеншна здесь нет софтмакса, вместо него используется сигмоида, а полученные скоры поэлементно перемножаются с V.
Обучение и инференс
На обучении lookup table шардируют между девайсами, для пересылки нужных эмбеддингов используют all-to-all.
На инференсе таблицу можно вынести в RAM+disk, потому что её не нужно обновлять, только читать. Чтобы не проседал throughput, подсчёты Engram накладывают на основной forward pass: на вход модуля идут токены, значит часть эмбеддингов можно заранее преподсчитывать. В итоге для lookup table на 100B параметров потери по throughput < 3%.
Дополнительной памяти на Engram-модуль не требуется, так как параметры для него берут у неактивных экспертов MoE.
Эксперименты
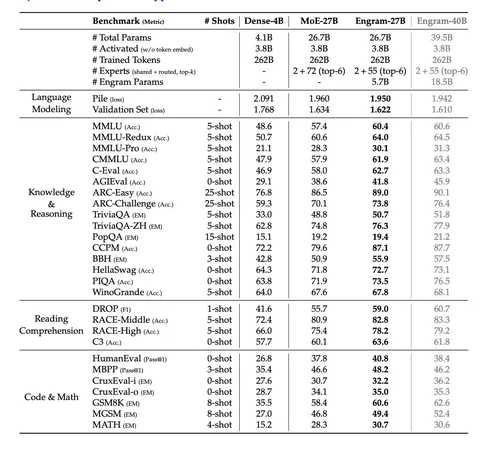
Минимальный лосс получается, когда четверть неактивных параметров уходит в Engram. Это протестировали на двух бюджетах FLOPs.
На большой Engram-27B-модели метрики растут не только на knowledge-intensive-задачах, но иногда ещё сильнее на reasoning, math и code. На бенчмарках с длинным контекстом тоже получаются лучшие метрики.
Также проводят sensitivity-анализ, зануляя выход Engram-модуля, и видят, что сильнее всего это бьёт по задачам, требующих factual knowledge.
Так получается, потому что у модели увеличивается effective depth: ранним слоям не нужно заниматься knowledge lookup (имитировать его), и больше слоёв теперь могут «думать».
Самыми важными компонентами Engram-модуля оказываются branch-specific fusion (свой W_K для каждой ветки в mHC-архитектуре), context-aware gating и tokenizer compression. Меньше влияют свёртка и добавление 4-граммы (при условии, что будут делить общий бюджет параметров с 2- и 3-граммами).
Разбор подготовил Никита Курдюков из Т-Банка
Душный NLP