В первой части разбора мы говорили о методах оптимизации KV-кэша в принципе. А сегодня речь пойдёт об одном конкретном подходе — ShadowKV.
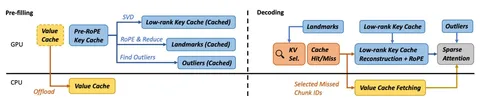
В его основе наблюдение, что post-RoPE key cache обладает attention locality — соседние токены часто имеют высокую cosine similarity, и только небольшая часть токенов выбивается из этого паттерна. Поэтому их режут на чанки по 8 токенов и строят landmarks — репрезентативные средние ключи для чанка. Это значительно ускоряет этап выбора ключей на шаге декодирования, а также улучшает доступ к памяти и позволяет лучше насыщать шину.
Ключевой момент в том, что лучше всего сжимается именно pre-RoPE K: он хорошо раскладывается в низкий ранг с минимальной ошибкой, заметно лучше, чем V. Поэтому ShadowKV делает так: pre-RoPE K сжимается через SVD, а V не сжимается, а уезжает в CPU (RAM), чтобы экономить GPU память и bandwidth.
При этом небольшое число токенов, которые плохо объясняются landmark’ами, выделяются как outliers (выбросы) и сохраняются полнорангово. В статье отмечают, что значимая доля outliers — это sink tokens. Достаточно порядка 0,049% бюджета на выбросы, чтобы попасть в точку diminishing returns: это минимальное количество outliers, которое почти полностью закрывает деградацию качества, а дальнейшее увеличение бюджета даёт лишь пренебрежимо малый дополнительный вклад.
На этапе prefill пайплайн строится так: параллельно с основным префиллом быстро вычисляются landmarks и outliers, и это вычисление перекрывается с отгрузкой V на CPU. В результате дополнительные шаги минимально увеличивают critical path, потому что большая часть работы делается в overlap-режиме.
Q на decode скорится не по всем токенам, а по landmarks каждого чанка. Затем выбираются лучшие чанки, и уже все токены из выбранных чанков отправляются в kernel attention. Для этого K восстанавливаются обратно из low-rank пространства, а соответствующие V подгружаются из CPU.
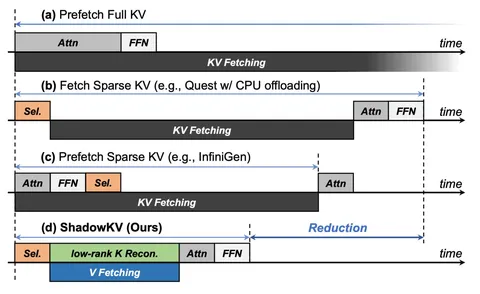
Дополнительно используется оптимизация в духе branch prediction или speculative-подходов. Между двумя соседними шагами декодирования выбранный набор токенов обычно меняется незначительно, потому что запросы на соседних шагах похожи. Поэтому можно кэшировать уже подгруженные токены для каждого слоя и на следующем шаге считать разность множеств, догружая только те токены, которых ещё нет в рабочем наборе. Эта оптимизация lossless относительно ShadowKV, потому что сохраняется инвариант: на каждом шаге в аттеншн всё равно попадает актуальный набор токенов — просто часть из них переиспользуется без повторной загрузки.
На бенчмарках деградация остаётся минимальной при бюджете около 1,56% от полного объёма KV. При этом в практических сценариях ShadowKV обеспечивает заметный прирост скорости и позволяет поддерживать существенно больший размер батча — за счёт снижения нагрузки на VRAM и уменьшения стоимости аттеншн на длинных контекстах.
Отдельно важно понимать, почему вообще имеет смысл оптимизировать именно аттеншн. Его вычислительная стоимость растёт с длиной последовательности, и на длинных контекстах он начинает доминировать по времени, тогда как FFN от длины контекста почти не зависит. Поэтому на коротких последовательностях в профиле часто доминирует FFN, и ускорение аттеншена даёт небольшой выигрыш.
Зато на длинных контекстах бутылочным горлышком становится аттеншн, и тогда по закону Амдала даже частичное ускорение этой части даёт заметную экономию общего E2E-времени инференса.
Разбор подготовил
Душный NLP