В эпоху агентов, ризонинга и мультимодальности длинные контексты начинают играть всё более значимую роль. Привычный нам softmax attention из-за своей квадратичной зависимости от длины контекста сильнее влияет на эффективность обучения и инференса.
Для решения проблемы квадратичности попробовали обратиться к RNN. Так появился новый класс аттеншнов — linear attention. Как следует из названия, они зависят от длины контекста линейно, что делает их в разы эффективнее на больших контекстах. Но модели, которые используют только linear attention, плохо справляются с retrieval-задачами (ещё вернёмся к этому вопросу в посте).
Объединив лучшее из двух подходов, ML-разработчики получили гибриды. Сегодня разберём, как они устроены, на примере одной из самых хайповых современных моделей — Qwen3-Next.
Вспомним, что представляют из себя современные линейные аттеншны. По сути, это RNN, только вместо векторного состояния — матричное, побольше. Ещё в линейных аттеншнах есть механизмы забывания — гейты. Вместо того, чтобы как полный аттеншн хранить весь прошлый контекст в KV-cache (который растёт с увеличением длины последовательности), линейные аттеншны учатся сжимать весь контекст в стейт фиксированного размера. А гейты помогают лучше регулировать, что запомнить и забыть.
Но бесплатный сыр бывает только в мышеловке: из-за сжатия контекста в стейт фиксированного размера в линейных аттеншнах нет доступа ко всей исходной последовательности. То есть, точно скопировать рандомный токен не получится. Поэтому-то и страдают задачи retrieval и копирования. Но чтобы справиться с этим, достаточно нескольких слоёв с полным атеншеном.
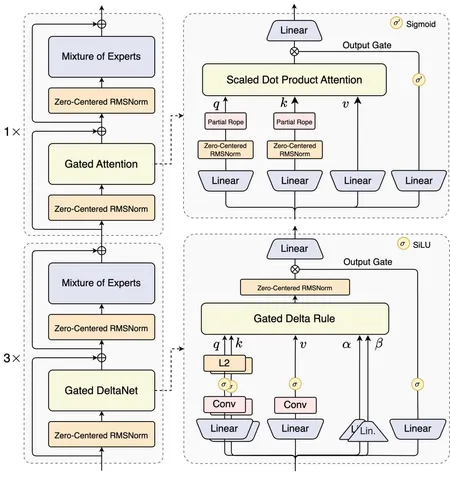
Вернёмся к Qwen3-Next. Рассмотреть её архитектуру можно на схеме. Три четверти слоёв — линейный атеншен в лице Gated DeltaNet. 3/4 — довольно распространенная пропорция. Также в этой архитектуре проапгрейдили обычный полный аттеншн с помощью swiglu-like-гейтинга. Это улучшило качество и решило проблему с attention sink.
Partial Rope, как следует из названия, «крутит» только часть хидденов головы. В Qwen3-Next только четверть хидденов головы получает информацию о позиции в последовательности. По словам авторов, это позволяет лучше экстраполироваться при увеличении контекста.
Zero-Centered RMSNorm математически эквивалентен обычному RMSNorm. Единственное отличие — веса инициализируются нулями, а не единицами, и потом на форварде к весу прибавляется 1. Формально это одно и то же, но из-за того, что веса теперь у нуля, где выше гранулярность float’ов, численная стабильность улучшается. Ещё более важно, что это позволяет использовать WD для весов в RMSNorm: некоторые веса становились слишком большими, добавление WD улучшило стабильность обучения.
Sparsity очень высокая — 1/50. Для масштаба, у DeepSeek она составляет 1/32, у Qwen235B — 1/16. Из 80B параметров активны только 3B.
Познакомиться с Qwen3-Next поближе можно на HuggingFace. А ещё недавно вышла новая линейка моделей, основанная на той же архитектуре — Qwen3.5. В текущем опенсорсе это SoTA.
Разбор подготовил
Душный NLP