В прошлый раз мы рассмотрели несколько классических методов мёржинга: усреднение весов, SLERP и TIES. В этом посте завершим обзор ещё двумя не менее интересным способами.
Итак, метод DARE схож с TIES, но избавляются здесь не от слишком маленьких, а от случайных изменений. Можно выкинуть до 90% значений без ущерба для качества. Дальше нужно действовать как в методе SLERP, о котором мы рассказывали в прошлом посте, а затем необходимо скалирование весов, чтобы сохранить их среднюю магнитуду.
К классическим (но извращённым) методам слияния также относится Passthrough. Модели, созданные с его помощью, ещё называют «Франкенштейнами» — и это неудивительно. Passthrough предполагает простую замену слоёв одной модели слоями другой.
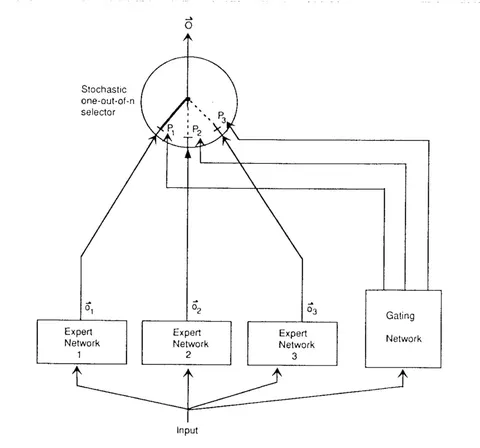
Самый популярный метод сейчас — это MoE (Mixture of Experts). Суть его заключается в замене FFN-слоев на «смесь экспертов». В таком случае каждый токен отправляется «эксперту», которому больше всего подходит. Распределением занимается роутер. Его можно инициализировать случайно и дообучить. Схему можно увидеть выше.
Но есть вариант и без дообучения. Скажем, у нас есть несколько моделей. Для каждой из них выберем промты, на которых она лучше всего работает. Для промтов можно предпосчитать среднее скрытое представление, а затем сравнить со скрытым представлением токенов, которые подаются в модель. Если они схожи — эксперты получают соответствующие токены. А чтобы определить похожесть достаточно прибегнуть к простому скалярному произведению.
Мы перечислили далеко не все методы мёржа — эта сфера развивается и эволюционирует как живой организм. К тому же, мы не углублялись в подробности каждого способа, а лишь описали их в общих чертах. Рассказывайте в комментариях, какими вы пользовались сами и какие вам кажутся самыми эффективными?
Душный NLP