Решение из сегодняшней статьи от Meta* — конкурент другой разработки по квантизации в низкую битность, QuaRot. Но в SpinQuant, кроме весов и активаций, квантуется ещё и KV-кэш. Иными словами, это SOTA-результат w4a4kv4-квантизации, который показывает очень хороший перфоманс даже на «макбуках».
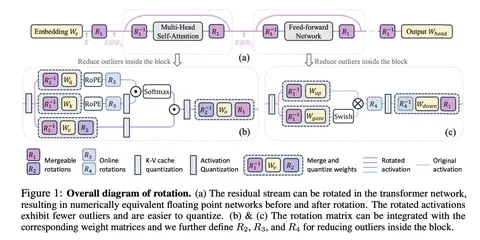
Главная идея — победить проблемы выбросов (поканальных отклонений в активациях attention), добавив матрицы поворота до и после каждого линейного слоя модели. После этого квантизация проводится как обычно, но без потери качества — спасибо обучаемым, а не случайным, как в QuaRot, матрицам вращения (розовые R₁ на рисунке).
Но ничего не бывает бесплатно: умножение — отдельная операция, которая требует дополнительных ресурсов. Чтобы сэкономить в момент инференса, матрицы вращения R₁ вмёрживаются в матрицы весов W умножением. Но так получается сделать не для всех вращений: например, матрицы R₃ и R₄ вставляют в слой отдельной операцией и, как в статье QuaRot, — используют случайные матрицы Адамара.
*Компания Meta признана экстремистской организацией в России.
Разбор подготовил
Душный NLP