Сегодня разберём статью о новой диффузионной модели от китайских коллег. Модель относится к классу так называемых дискретных диффузий и очень похожа на BERT в режиме Masked Language Modelling.
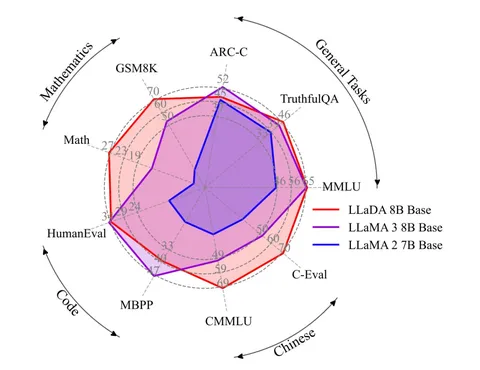
Авторы называют свою разработку LLaDA. На графике — диаграмма сравнения новой модели (красная кривая) с LLaMA 3 8B (фиолетовая кривая) и LLaMA 2 7B (синяя кривая). К скейлу осей есть вопросы:
∙ там, где LLaDA показывает лучшие результаты — разница выглядит значительной;
∙ там, где LLaDA хуже, — различия выглядят несущественными.
Возможно, на площади под кривыми смотреть бессмысленно и график не очень репрезентативный. Но с долей критики по нему вполне можно ориентироваться в сильных и слабых сторонах новой модели.
В языковом моделировании уже давно правит бал классическая авторегрессия, где каждый последующий токен моделируется вероятностным распределением и обусловлен на контекст. Но такой подход не лишён недостатков: если первый токен, который породила модель, оказался не самым удачным, исправить ошибку уже не получится — модель продолжит генерировать следующие токены, оглядываясь на первый, и испортит весь ответ.
Бороться с этой проблемой можно, например, с помощью chain-of-thoughts. Но существует и ортогональное решение — использовать диффузионный подход с некаузальной маской аттеншна.
Как? Читайте в следующей части разбора.
Разбор подготовил
Душный NLP