Продолжаем разбирать, что внутри у китайской модели LLaDA (начинали вот тут).
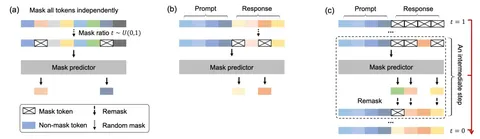
Обучение (иллюстрации (a) и (b))
Диффузия, как известно, учится восстанавливать объекты из шума. И LLaDA — не исключение. Для каждого батча обучения она сперва генерирует долю токенов t (от 0 до 1), которые хотим зашумить. А затем маскирует токены в батче с этой вероятностью.
Далее модель обучается восстанавливать замаскированные токены. Стадия предобучения и SFT отличаются лишь тем, что в SFT зашумляется только ответ, но не запрос. Чтобы модель умела восстанавливать последовательности разной длины, в обучение специально подкладывается 1% текстов с длинами от 1 до 4096 токенов.
Генерация (иллюстрация (c))
Модель начинает генерацию ответа с запроса и полностью замаскированного ответа — такое состояние соответствует моменту времени t = 1 (начальной стадии восстановления текста). На каждом шаге генерации все замаскированные токены восстанавливаются одним проходом модели (токены выбираются жадно). А затем часть предсказанных токенов вновь маскируется с вероятностью t.
t постепенно уменьшается до тех пор, пока не дойдёт до 0. Итеративный подход предсказал — зашумил позволяет модели лучше обдумать, что именно она собирается генерировать.
Также авторы хорошо отзываются о подходе, где маскирование предсказанных токенов происходит не случайно, с какой-то вероятностью, а детерминировано — маскируется доля t токенов, в которых модель наименее уверена. Этот подход к генерации также совместим с classifier-free guidance, что не может не радовать.
LLaDA — далеко не первая модель, основанная на Masked Language Modelling. Хотя авторы и не предложили миру радикально новый подход, простота и изящность идеи позволила им догнать и перегнать весьма сильные авторегрессионные бейзлайны: LLaMA 2 и 3.
Разбор подготовил
Душный NLP