MIA-Bench: Towards Better Instruction Following Evaluation of Multimodal LLMs
Неплохой бенчмарк на следование инструкциям, но уже достаточно простой для топ-моделей. Автор говорит, что команда старалась сделать его не субъективным, и утверждает, что на небольшом семпле LLM работает с точностью выше 90%.
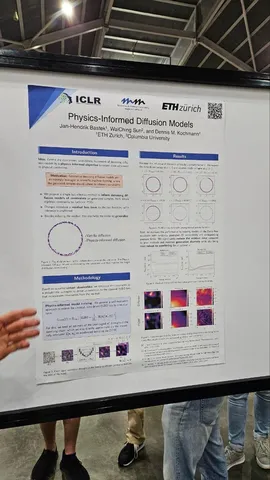
Physics-Informed Diffusion Models
Авторы говорят, что раз PINN'ы до сих пор нормально не работают, можно попробовать добавить физические ограничения в диффузионки. На простых примерах выглядит хорошо (но и PINN'ы были неплохими), а как будет на сложных — пока непонятно.
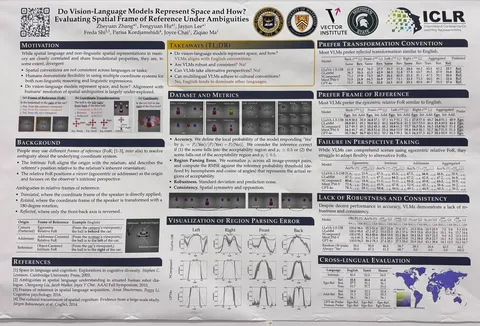
Do Vision-Language Models Represent Space and How? Evaluating Spatial Frame of Reference Under Ambiguities
Статья об изучении пространственных bias’ов в VLM. Оказывается, они плохо отвечают на вопросы про расположение с чьей-то перспективы (например, если рассматривать расположение относительно камеры или другого объекта в кадре). При этом в разных языках такое описание взаимного расположения объектов может строиться по-разному. И VLM, конечно же, смещены в сторону того, как это работает в английском, даже если они мультилингвальные (что потенциально ведет к проблемам с языками с другой системой описаний).
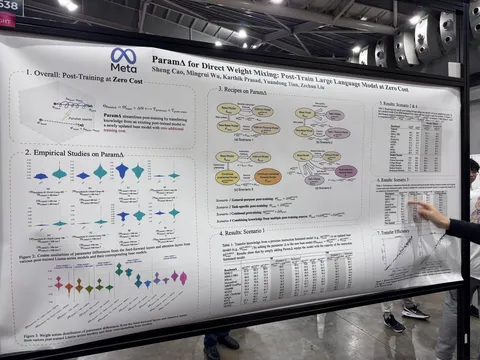
Param∆ for Direct Weight Mixing: Post-Train Large Language Model at Zero Cost
При обновлении бейзлайна LLM (например, с v1 на v2, если у них не изменилась архитектура) можно не переобучать его под задачу, а вычесть веса старого бейзлайна (v1), добавить веса нового (v2) и радоваться жизни с таким «бесплатным» обучением. Работает хуже дообучения на новом бейзлайне, но лучше, чем отсутствие дообучения. Авторы экспериментировали только с Llama 3, Llama 3.1 и полным файнтьюном модели под задачу.
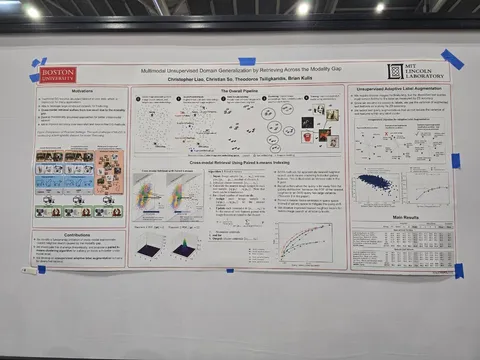
Multimodal Unsupervised Domain Generalization by Retrieving Across the Modality Gap
Улучшают ANN через уточнённые эмбеддинги объектов на основе аугментации текстов, описывающих интересующие классы. Центроиды картинок смещаются к их усреднённым положениям относительно эмбеддингов аугментированных запросов.
Работы отобрали и прокомментировали
CV Time
#YaICLR