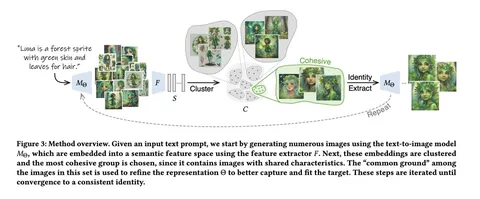
Сегодня разбираем статью, которая предлагает не самый практичный, но достаточно любопытный способ заставить генеративную модель выдавать одного и того же персонажа при разных промптах. Например, это важно для сторителлинга и комиксов, где герой должен сохранять идентичность во всех сценах.
Основная идея статьи — добиться того, чтобы по одному текстовому промпту всегда генерировался один и тот же персонаж. При стандартной генерации «ёжика-альбиноса с фиолетовыми иголками» без подготовки получаются разные ёжики: похожие, но отличающиеся в деталях. Обычно задачу решают через DreamBooth или текстовую инверсию на одной картинке, но это ведёт к жесткому переобучению и потере вариативности окружения.
Авторы предлагают другой путь. Они не используют исходное изображение и работают только с текстом. Сначала генерируют 128 картинок по одному промпту (SDXL), затем извлекают эмбеддинги через DINOv2 и выполняют кластеризацию. Выбирают самый крупный и плотный кластер — там образ героя выглядит максимально однородно. На этом подмножестве проводят fine-tune модели с помощью LoRA и текстовой инверсии, после чего повторяют цикл генерации, кластеризации и обучения ещё четыре–пять раз. Процедура занимает около 24 минут на одной GPU.
Так удаётся зафиксировать ключевые черты персонажа — цвет кожи, форму глаз, аксессуары и даже позу, хотя фон при этом остаётся неизменным. При смене промпта обучение придётся повторить: метод жёстко привязан к тексту.
Сравнение с базовыми методами:
- Vanilla Textual Inversion — образы слишком разнородны;
- DreamBooth full fine-tuning — модель переобучается на фон и перестаёт менять окружение;
- текстовая инверсия через LoRA: недообучается, даёт слабую консистентность.
В итоге этот метод («Sauce») позволяет получить баланс между соответствием промту и стабильностью образа. Auto-метрика CLIP-Score и оценки на Amazon MTurk подтвердили, что согласованность растёт без серьёзных потерь в точности при сохранении разнообразия фонов и поз.
Абляционный анализ показывает, что без кластеризации модели не сохраняют образ. Одна итерация обучения даёт малозаметный эффект, а при реинициализации весов каждую итерацию результаты ухудшаются.
Метод совместим с другими техниками: при генерации истории из четырёх промптов герой остаётся постоянным; с ControlNet можно задать новую позу, сохранив лицо, а сочетание с DreamBooth и LoRA улучшает детализацию.
Основные ограничения связаны с тем, что кластер может захватить фон или часто встречающиеся детали — котик может «прилипнуть» к листикам, а позы и окружение мешают выделить только лицо героя. Авторы предлагают предоставить пользователю выбор из нескольких кластеров.
В перспективе авторы хотят расширить подход для работы с реальными фотографиями: сначала получить текстовое описание через captioning, затем применить тот же цикл генерации, кластеризации и дообучения.
Немного технических деталей: 128 изображений, 500 шагов обучения с AdamW, порог плотности кластера — 0,8 от медианной дистанции с адаптивным подбором на первой итерации.
В заключение можно подметить, что метод хоть и интересный, но на практике требует много времени и ресурсов, а результат всё же далёк от идеала. Но сама идея итеративной кластеризации и дообучения модели заслуживает внимания.
Разбор подготовил
CV Time