Сегодня разбираем статью о Nexus-Gen — мультимодальной модели от Alibaba, которая задумывалась как полностью открытая: авторы выложили не только код и веса, но и датасет. Модель умеет генерировать и редактировать изображения по текстовым запросам.
Качество картинок в целом достойное, хотя не всегда удаётся сохранить идентичность объектов при редактировании: при простых изменениях могут искажаться второстепенные детали — например, у человека слегка меняются черты лица, а в интерьере исчезают или трансформируются объекты, которые трогать не просили.
Архитектура
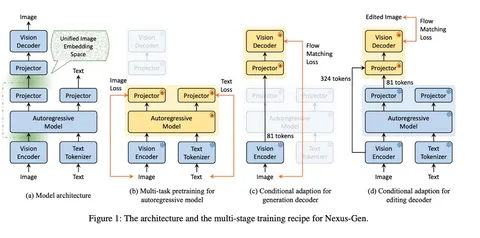
В основе модели авторегрессор (Qwen-2.5-VL) в связке с визуальным энкодером и декодером на базе Flux. Архитектура вдохновлена UniFLUID: текст и изображение проходят через общий авторегрессор, а для визуальной части используется отдельный визуальный декодер. В новой версии также добавлен декодер для редактирования изображений, который работает вместе с генеративным.
Главное улучшение модели связано с проблемой накопления ошибок на непрерывных визуальных токенах. В отличие от текста, где токены дискретны и ошибки не накапливаются, изображения страдают от смещения при последовательной генерации патчей. Авторы предложили решение: ввести специальный обучаемый токен, который обозначает места для генерации визуальных патчей. При обучении он вставляется в последовательность, а при инференсе автоматически генерируется и подаётся в диффузионную голову. Таким образом, модель всегда работает с фиксированным токеном, не накапливая ошибок с предыдущих шагов.
Для обучения используется комбинация лоссов: кросс-энтропия для текстовых токенов, MSE и косинусная близость — для визуальных. Это позволяет согласовать пространство визуального энкодера и выходы авторегрессора, сохраняя совместимость с диффузионной частью.
Этапы обучения
Сначала модель училась на задачах image understanding и image generation без учёта редактирования. На втором этапе задачи редактирования добавлялись в небольшом количестве. На третьем — к обучению подключили новый декодер для задач редактирования, а баланс сместился в сторону таких задач. На заключительном шаге проводили элайнмент между визуальными представлениями на входе и выходе авторегрессора, чтобы стабилизировать работу с диффузией и улучшить согласованность между генеративным и редактирующим декодерами.
Результаты
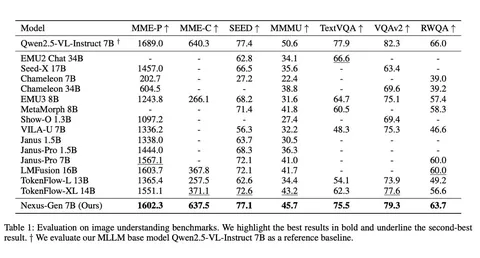
В новой версии Nexus-Gen авторы, наконец, показали количественные результаты: модель на 7B параметров занимает первое место на ряде бенчмарков по пониманию изображений, включая MME-P (1602,3) и TextVQA (75,5). Также она показывает высокий уровень на VQAv2 (79,3) и SEED (77,1), сопоставимый или превосходящий конкурентов ощутимо больших размеров. При этом она сохраняет баланс между пониманием, генерацией и редактированием.
Разбор подготовил
CV Time