Сегодня разбираем статью с любопытным методом разметки данных, который возвращает внимание модели к картинке, а не только к тексту.
При обучении на синтетике визуально-языковые модели быстро перестают смотреть на изображение и уходят в чисто текстовый ризонинг. Пример из статьи: нужно вычислить площадь под графиком. Текстовая модель пересчитывает шаги правильно, но не учитывает, что площадь под осью идёт с минусом. А модель с «визуальным рефлекшеном» может повторно взглянуть на картинку и заметить этот нюанс.
Чтобы показать проблему, в статье приводят несколько метрик. Первая — attention score между токенами рассуждения и визуальными токенами. Чем длиннее ризонинг, тем меньше внимания остаётся на картинку.
Вторая метрика — расстояние Хеллингера. Сначала запускают генерацию с картинкой, а затем убирают визуальные токены и продолжают без них. График показывает, что расстояние со временем уменьшается. Это значит, что итоговые генерации с убранной картинкой (после нескольких токенов, сгенерированных с изображением) почти не отличаются от генераций, где картинка присутствует. Иначе говоря, начиная с какого-то шага модель просто перестаёт использовать изображение и игнорирует его.
Авторы предлагают модель Reflection-V, которая умеет делать рефлекшн именно по изображению.
Решением становится новая разметка. Сначала составляется максимально подробный кэпшн, затем сильная текстовая модель (например, DeepSeek) выполняет задачу только по описанию.
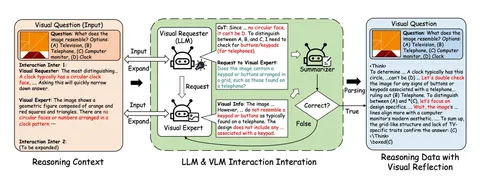
Но ключевая идея статьи — агентский пайплайн. LLM-агент получает задачу: «На что похожа фигура — на телевизор, телефон, компьютер или часы?». Он вызывает VLM и уточняет: «Похоже ли это на часы?». VLM отвечает: «Есть треугольники и квадраты, ничего круглого — не часы». Агент делает вывод: «Значит, может быть телефон — у него кнопки сеткой, как клавиатура», и снова уточняет. Так формируется диалог, который суммаризатор превращает в связный reasoning trace. В итоге рассуждение действительно опирается на картинку, а не на текст.
Дополнительно используются фильтрации: если агент ответил без обращения к VLM, пример удаляется. На собранных данных модель обучается с GRPO. К обычной награде за правильный ответ добавляется ещё одна — по attention. Она измеряет, насколько во второй половине ризонинга модель продолжает опираться на изображение. Идея в том, чтобы не дать ей «забыть» картинку в середине рассуждения.
Тесты проводили на MathVision, MathVista, MMMU, IMMU-Pro, M3CoT и HallBench. Обучали две версии — Reflection-V-3B и Reflection-V-7B на базе Qwen2.5-VL. Они уверенно обгоняют опенсорсные ризонёры на синтетике и даже внутренние модели Qwen.
В агентской системе «мозгом» выступает QWQ-32B (LLM-reasoner), визуальным экспертом — Qwen-2.5-VL-72B. Обучение идёт в два этапа: сначала SFT (три эпохи на двух H100), затем GRPO (двенадцать эпох на восьми H100 через vLLM). Всего — около 16 тысяч ризонинг-семплов. Сетап скромный, особенно по объёму данных.
Аблейшны показывают, что полная модель (3B и 7B) даёт лучшие результаты.
Убираем reward по attention — метрики падают. Без SFT — ещё хуже. Убираем и то, и другое — совсем провал. Вывод авторов очевиден: все элементы нужны и каждый вносит свой вклад.
Разбор подготовил
CV Time