Сейчас индустрия унифицирует подходы к обработке различных видов данных. Существенную часть задач компьютерного зрения решают VLM: генерируют текст на основе изображений и запросов, которые получают на вход. Следующий шаг — наделить модели возможностью генерировать изображения.
Изображения, в отличие от текстов, недискретные, поэтому для них лучше применять вариации диффузионных лоссов, а не next-token prediction. Сегодня рассмотрим статью, где предлагается объединить в одной системе два лосса.
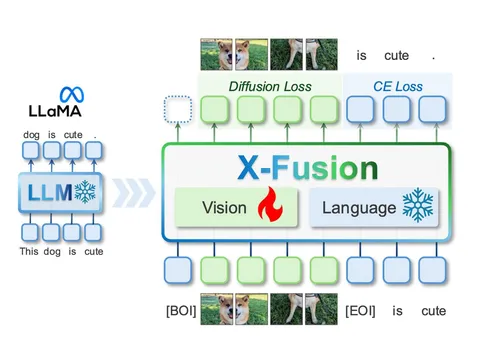
Суперверхнеуровневая схема нового фреймворка X-Fusion — на иллюстрации к посту. Авторы предлагают использовать две одинаковых предобученных LLM: первую заморозить, чтобы она стабильно хорошо справлялась с текстовыми задачами. А её копию — назвать визуальной башней и дообучить для работы с изображениями.
Если нужно обработать изображение, то закодируем его VAE от SD-1,5 и подадим на вход визуальной башне. Таким образом, генерация текста происходит через предсказание следующего токена. А для создания изображений выберем токены, расшумим их диффузией и декодируем VAE.
Авторы сравнили четыре базовые архитектуры:
— Единообразно обрабатывать текстовые и картиночные входы одним трансформером.
— Дублировать каждый слой LLM-gated-слоем. Обучать только визуальные слои, результаты складывать, а визуальный выход домножать на обучаемый скаляр.
— Схема с двойной проекцией: копировать и добучать QKV-матрицы и MLP для визуальной модальности.
— Финальный вариант: две башни, одна из которых применяется для текстовой модальности, а вторая — для визуальной. А потом либо использовать (в целях экономии вычислений) выходы из соответствующих башен, либо суммировать их с некоторыми весами.
X-Fusion обучали на синтетике: caption сгенерировали InternVL-2.0 26B. А для text-to-image взяли свой inhouse-датасет. Хотя по словам авторов, подход с двумя башнями превосходит другие базовые решения в задачах создания изображений, в обратную сторону это не работает: задача генерации текста не помогает получать хорошие caption для изображений. Авторы также изучают, стоит ли зашумлять входные латенты для задач распознавания изображений. Их вывод — нет, это приводит к деградации качества.
Разбор подготовил
CV Time