Сегодня начинаем разбирать недавнюю статью DeepSeek-OCR. Авторы работы сфокусировались на двух аспектах:
1. обучении эффективной VLM-модели, заточенной именно под OCR-задачи;
2. изучении влияния размера входного изображения на качество работы VLM (и компрессии визуальной информации в целом).
Сначала небольшое интро по каждому из этих аспектов.
OCR-специфичные VLM-модели
Задачи, связанные с чтением текста, встречаются довольно часто и у простых пользователей, и в бизнес-процессах компаний. Такие задачи не требуют знания фактов, агентности, рассуждений, и тратить много GPU на них жалко. За последний год вышло несколько статей по OCR-специализированным легковесным VLM (GOT, Dolphin, UMiner, dots.ocr).
Динамическое разрешение в VLM
Первые VLM, вроде LLaVA, использовали статический размер изображения: любая картинка для обработки ресайзилась к фиксированному квадрату, прогонялась через энкодер (например CLIP), готовя картиночные токены на вход LLM. Так как изображение на входе может быть и пиксельной строкой текста 128 х 16, и большим фото со смартфона 1500 х 4500 пикселей — статический размер работает не оптимально. Сегодня для VLM есть два основных способа сделать разрешение динамическим:
1. Tile-based-resolution (Intern-VL2) — изображение разрезается на квадраты, например 512х512 пикселей, и каждое прогоняется через картиночный энкодер. Все выходные токены (чем больше размер — тем больше тайлов и токенов) подаются на вход LLM.
2. Native-resolution (Qwen-VL2) — картиночный энкодер обучается принимать на вход изображение любого размера, используя подходящие для этого позицинные эмбеддинги типа RoPE.
Модель и данные
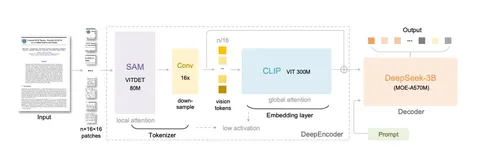
DeepSeek-OCR архитектурно повторяет стандартную для VLM схему: картиночный энкодер, присоединенный к предобученной LLM (в этом случае DeepSeek-3B).
Однако вместо стандартного CLIP/SigLIP в качестве энкодера используется пайплайн из SegmentAnything (SAM-ViT-Det), свёрточного адаптера и CLIP (CLIP-ViT), который в статье называют DeepEncoder. Авторы хотели, чтоб энкодер был эффективным и быстрым, и чтобы в уже обученном энкодере можно было легко «на лету» менять количество картиночных токенов.
SAM-ViT-Det может принимать на вход изображение любого размера; токенизированные патчи обрабатываются независимо друг от друга благодаря window attention — поэтому количество вычислений уменьшается. Затем адаптер снижает количество токенов в 16 раз, а после глобальный аттеншн в CLIP-ViT агрегирует их вместе.
Для обучении используется типичная смесь пар (картинка-описание) и только текстовых данных с упором на OCR: печатный текст, графики и таблицы, формулы. В отличие от других OCR-специализированных VLM (обычно обучаемых только на английском и китайском), датасеты содержат более 100 языков.
Во второй части подробнее разберём, как обучали DeepSeek-OCR и к каким результатам пришли авторы.
Разбор подготовил
CV Time