Конференция продолжается, а наш коллега Владислав Фахретдинов делится заметками о воркшопе второго дня — 7th International Workshop on Large Scale Holistic Video Understanding: Toward Video Foundation Models.
Было немного спикеров, но почти каждый привёз по две-три статьи или исследования, поэтому день получился насыщенным. Основной мотив воркшопа — большинство моделей для работы с видео недостаточно хорошо ориентируются «во времени». Участники разбирались, что с этим можно сделать.
Первым выступил профессор университета Амстердама. Он заметил, что многие VideoLLM не справляются даже с простым синтетическим бенчмарком: какой из двух объектов в видео появляется раньше. Это показывает, что мы до конца не понимаем, как правильно оценивать такие способности модели.
Затем последовал рассказ о работе Bench of Time с более подробными исследованиями — оказалось, что большинство примеров в популярном бенчмарке (MVBench) решается либо знанием всего об одном кадре, либо вообще исключительно по тексту. Чтобы исправить эту ситуацию, авторы сделали свой бенчмарк TVBench. В нём все вопросы были сформулированы так, что без понимания объектов и процессов в кадре нельзя дать правильный ответ.
Сравнение моделей на новом бенчмарке показало, что большинство языковых, картиночных и даже видеомоделей выдают результаты немногим лучше случайного предсказания. При этом все же нашлись несколько моделей, которые были достаточно хороши на обоих бенчмарках, например Gemini-1.5.
Следом было выступление о генерации 3D-представления из изображения. По сути, это продолжение работы DUSt3R, в которой научились по любым входным изображениям без параметров камер и поз делать матчинг и генерировать плотное облако точек 3D-представления сцены.
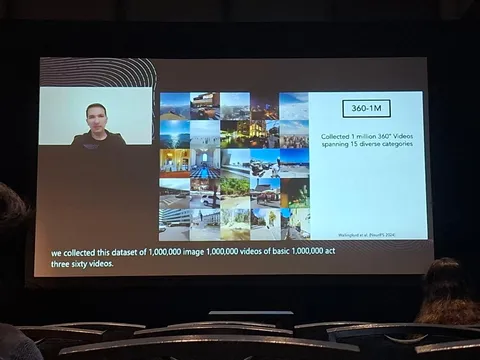
Авторы сделали уточнение, что матчинг изображений по случайному видео с движением — вычислительно сложная задача. Поэтому они собрали датасет 360-1M, где происходит движение и вращение вокруг оси, из-за чего матчить изображения стало гораздо проще. На основе своего датасета они обучили генеративную модель ODIN, которая по изображению и смещению позиции камеры генерирует новое изображение. Подробностей было мало, никаких сравнений с DUSt3R или NeRF не показали, но зато рассказали, что модель хорошо обобщается вне домена — например, на картины.
Самый интересный доклад за день — о том, что визуальные модели знают о нашем мире. Авторы выделили и проверили три свойства: базовое представление о физическом устройстве мира, визуальное предсказание, а также обобщение — понимание аналогий.
Для первого свойства взяли часовые видео с прогулками по городам и с помощью сервиса визуальной локализации, а также небольшого объёма человеческой проверки, разметили эти видео. В частности, для каждого видео сгенерировали маршрут на карте.
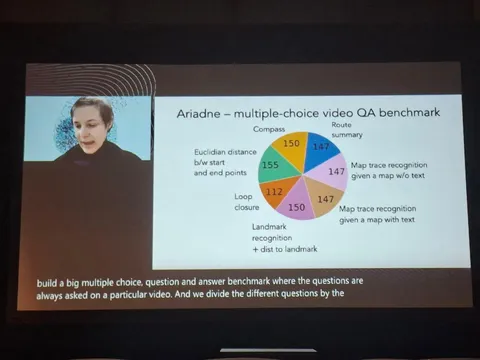
Далее видео нарезали и собрали бенчмарк, в котором модели задавали вопросы по содержанию ролика, например: о евклидовом расстоянии от начальной до конечной точки на полученном маршруте; направлении; зацикленность маршрута; выборе правильного трека на карте среди нескольких вариантов (с текстом на карте и без текста); распознавании окружающей архитектуры. По всем этим вопросам модели уступают человеку — за исключением проверки на зацикленность маршрута.
Авторы также показали, что на самом деле модели не понимали, был цикл в маршруте или нет. Вместо этого они просто смотрели на разметку на карте и сопоставляли её с текстовыми названиями улиц, которые видны в видео.
Напоследок был доклад из трёх частей, из которых я бы выделил как самую интересную — SSL-обучение мультимодальной модели видео+аудио CAV-MAE Sync. Из того, что мне кажется важным: авторы совместно используют аудио- и видеопатчи и добавляют регистровый токен, чтобы переносить накопленную информацию в следующие слои. Больше всего мне понравилось, что новая модель позволяет локализовать на видео источники звука.
#YaNeurIPS25
CV Time