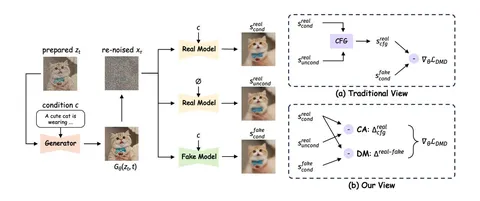
Сегодня разберём статью, авторы которой возвращаются к идее DMD и пытаются понять, что именно заставляет этот метод работать. Их главное наблюдение — главную роль в обучении играет не distribution matching, как можно было ожидать, а CFG Augmentation.
Что такое DMD
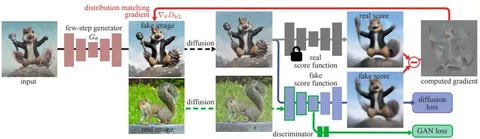
DMD относится к ODE-free-дистилляции диффузионных моделей: здесь не важно, по какой траектории происходит сэмплирование, главное — чтобы модель умела выдавать скор-функцию.
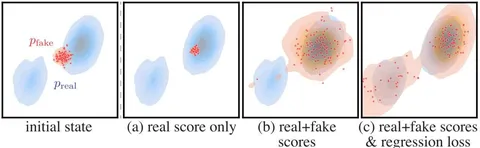
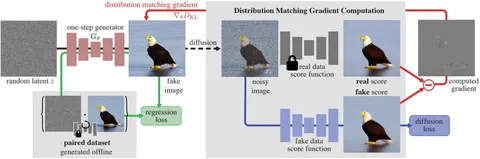
Идея метода в том, чтобы форсить совпадение распределения генератора с распределением реальных данных, оптимизируя KL-дивергенцию между P_{fake} и P_{real}. Плотность реальных данных напрямую недоступна, но для обучения достаточно градиента этого лосса. После дифференцирования в выражении появляются скор-функции реальных и фейковых данных: фейковую мы учим, а реальную аппроксимируем замороженной моделью-учителем.
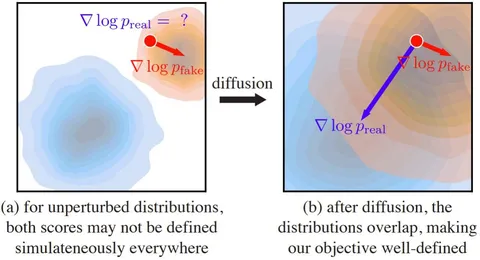
Поскольку скор-модели плохо работают на незашумлённых изображениях и реальные с фейковыми распределениями часто плохо пересекаются по модам, в DMD скоры считают на зашумлённых данных. Это делает их in-distribution и стабилизирует обучение. В итоге реальный скор остаётся замороженным, а фейковый обучается стандартным diffusion loss — это база для всех модификаций DMD.
Что изменилось в DMD2
В DMD2 авторы разомкнули обучение генератора и оценщика. Сделали несколько шагов обучения оценщика на один шаг генератора, и за счёт этого отказались от регрессионного лосса. Также был добавлен GAN loss как регуляризация: используют не как основной источник сигнала, а именно для стабилизации обучения.
Основная идея Decoupled DMD
В новой статье авторы снова смотрят на градиент KL-дивергенции и замечают, что простая conditional-оценка реального скора работает плохо. Зато на практике гораздо лучше CFG-оценка. Возникает вопрос — это просто удачный трюк или за этим стоит какая-то теория?
Оказывается, если подставить CFG прямо в формулу KL-лосса, он раскладывается на две части: классический distribution matching и дополнительный член, соответствующий вектору между real conditional и real unconditional скорами. Именно эту добавку авторы называют CFG Augmentation. Из этого разложения следует ключевой вывод статьи: основной обучающий сигнал в DMD даёт CFG Augmentation, а distribution matching выступает стабилизирующей регуляризацией.
Эксперименты и выводы
Эксперименты подтверждают этот тезис. Обучение только на distribution matching быстро ломает семантику, обучение только на CFG Augmentation приводит к переобучению. Самый стабильный результат получается при совместном использовании обоих компонент лосса.
Авторы также показывают, что CFG Augmentation и distribution matching имеет смысл обучать с разными уровнями шума: больший \tau в CFG-части помогает с высокочастотными деталями, тогда как для distribution matching лучше работает стандартный диапазон шумов.
В итоге статья интересна не столько метриками, сколько самим наблюдением: CFG в DMD — это не эвристика, а осмысленный компонент лосса.
Разбор подготовил
CV Time