Некоторое время назад мы обсуждали MLLM. Сегодня разберём статью о ещё одной универсальной модели, способной обрабатывать и текст, и изображения.
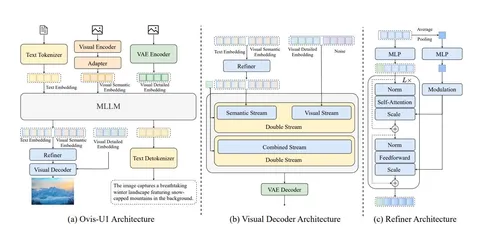
Ovis-U1 — модель-швейцарский-нож. В зависимости от инструкции, она может работать и в режиме image-to-text, и в text-to-image. Например, можно изменить изображение, описать его или сгенерировать совсем новую картинку по текстовому запросу. Архитектуру MLLM можно рассмотреть на первой из трёх схем.
Следите за логикой сверху вниз:
1. Сначала Ovis-U1 обрабатывает входные данные: токенизирует текст и обрабатывает изображения визуальным энкодером, чтобы составить семантический эмбеддинг, или использует VAE-энкодер для составления детализированного представления.
2. Полученная последовательность подаётся в трансформер, инициализируемый с Qwen3-1.7B.
3. Для генерации изображения выходные токены текстов и семантических представлений входной картинки комбинируются с помощью пары трансформерных слоев (авторы называют это Refiner’ом, на схеме обозначено как (с)) и, вместе с VAE-эмбеддингами, отправляются в «визуальный декодер» на базе MMDiT. Эта часть инициализируется с нуля.
Обучение модели происходит в несколько этапов:
— Сначала предобучается визуальный декодер на задачу text-to-image-генерации. Все остальные части при этом заморожены.
— Следом предобучается адаптер между LLM и визуальным энкодером на задачи text-to-image-генерации, а также понимание и редактирование изображений.
— Потом на тех же данных визуальный энкодер и адаптер обучаются вместе.
— На следующей стадии всё, кроме визуального декодера, обучается на задачах понимания изображения.
— Далее на задаче генерации изображений обучается refiner и визуальный декодер.
— На финальном этапе визуальный декодер файнтюнится для задач text-to-image-генерации и редактирования изображений.
Авторы утверждают, что визуальный декодер на основе диффузии в сочетании с Refiner’ом позволяет генерировать изображения почти так же хорошо, как GPT-4o. Интересны ещё несколько замеров:
— 69,6 баллов в мультимодальном академическом тесте OpenCompass (что лучше последних современных моделей, такие как Ristretto-3B и SAIL-VL-1.5-2B);
— 83,72 балла и 0,89 балла при преобразовании текста в изображение в тестах DPG-Bench и GenEval;
— 4,00 и 6,42 для редактирования изображений в ImgEdit-Bench и GEdit-Bench-EN.
Разбор подготовил
CV Time