Ещё летом 2025-го вышли текстовые Qwen3-Embedding/Reranker. А в январе этого года команда Qwen представила новые модели: Qwen3-VL-Embedding и Qwen3-VL-Reranker. В техрепорте авторы рассказывают, как им удалось адаптировать VLM для решения задач мультимодального поиска и ранжирования — ключевых тем ML с долгой историей развития и огромным количеством применений. Об этом сегодня и поговорим.
Формулировка задачи
Если кратко, задача поиска по базе документов — по запросу Q среди множества документов D[i] найти подходящие под запрос. В текстовом поиске Q и D — текст, а в мультимодальном варианте — Q и D могут быть картинками, текстом или их комбинацией, причём модальности Q и D могут не совпадать. Например, по запросу «пингвины в Южной Америке» релевантны и статьи Википедии, и соответствующие фотографии.
Модели
Один из распространённых подходов в решении задачи поиска — разбиение на два этапа: быстрый поиск кандидатов и более сложное ранжирование их между собой для определения лучших. Исходя из такой схемы, команда Qwen подготовила две модели:
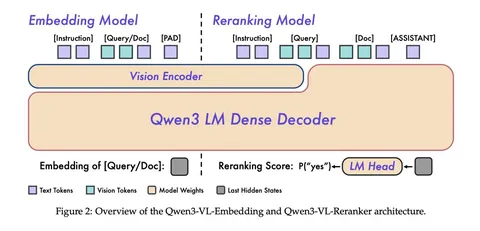
1. Qwen3-VL-Embedding: модель, предсказывающая для документа или запроса вектор признаков в соответствии с инструкцией. Можно считать,
`def embedding(instruction: str, query_or_doc: str | Image) -> list[float]`.2. Qwen3-VL-Reranker: модель, оценивающая согласно инструкции степень соответствия запроса документу от 0 до 1. Интерфейс примерно:
`def reranker(instruction: str, query: str | Image, document: str | Image) -> float`.Архитектурно модели — почти точные копии VLM: получают на вход токенизированные инструкции и текст, патчи изображений, но имеют модифицированный выход, и инференсятся несколько иначе.
Reranker выполняет инференс всей VLM целиком, но на выходе в качестве оценки «релевантен ли документ запросу» берётся соотношение вероятностей токенов “yes” и “no”. Embedding выполняет инференс до последнего слоя (проекции токена в вероятности вокабуляра) — и hidden state перед этой проекцией возвращается как эмбеддинг.
В отличие от полноценных VLM, в Embedding и Reranker выполняется только этап prefill (обработка входного контекста), и состояние последнего токена промпта возвращается как ответ. Стадия decoding (предсказания одного токена за другим) отсутствует, что делает инференс многократно быстрее.
Обе модели инициализируются Qwen3-VL и доступны в двух вариантах: на 2 и 8 миллиардов параметров.
Данные
Датасеты для поиска повторяют логику задачи:
— одна текстовая инструкция к задаче I;
— база мультимодальных документов D[i];
— набор мультимодальных запросов Q[j];
— матрица меток R[i, j], определяющих D[i] как релевантный или нерелевантный Q[j].
На таком датасете можно обучать как Reranker (напрямую классифицировать релевантность пары Q-D), так и Embedding (оценивая релевантность пары по скалярному произведению эмбеддингов).
Обучающий корпус Embedding и Reranker состоит из множества таких датасетов. Для каждого из них база документов берётся из реальных данных — эти документы VLM описывает и классифицирует. Некачественные фильтруются, распределение датасетов нормализуется, чтобы избежать сильного перекоса в какой-либо домен.
Затем для документов с помощью VLM генерируют запросы разных типов, причём как релевантные документу, так и hard-negative-примеры — запросы, для которых документ похож на релевантный, но не является таковым.
После этого датасеты дополнительно фильтруются уже существующими моделями и неудачные элементы датасета отсеиваются.
Во второй части разбора поговорим о том, как модели учились, и об их использовании на практике.
Разбор подготовил
CV Time