Продолжаем разбирать техрепорт, описывающий новые модели Qwen.
Обучение моделей и результаты
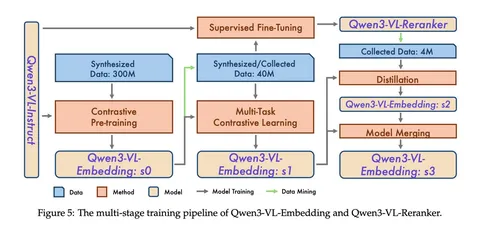
Обучение моделей делается в несколько этапов, причём довольно нетривиальным образом: модели с этапа X используются для последующей фильтрации данных для этапа X+1, а Embedding и Reranker на разных этапах выступают учителями друг для друга.
— На всех этапах модели обучаются как LoRA к Qwen3-VL, чтобы с большей вероятностью не испортить возможности сильного бэкбона.
— На первом этапе (s0) на всём датасете обучается Embedding, используя контрастивный InfoNCE-лосс.
— На следующем этапе Embedding:s0 используется для фильтрации датасета — и на этом фильтре обучается Embedder:s1 и Reranker.
— На последнем этапе снова фильтруется уже Reranker, и скоры Reranker используются как таргет для дистилляции Embedding:s2.
— Наконец, веса полученной модели усредняются (точнее, сферически интерполируются) с Embedding:s1, порождая финальную модель Embedding:s3, которая и пошла в релиз.
По замерам авторов, их модели опережают все существующие открытые и закрытые модели на мультимодальных бенчмарках. При этом на текстовых задачах есть и более сильные модели — в основном существенно большего размера.
Использование моделей
Авторы явно постарались сделать модели production-ready, позаботившись не только о качестве метрик, но и об удобстве использования.
Во-первых, в модель заложены несколько очень важных свойств для производительности (помимо инференса в один prefill-этап).
Тренировка проводилась в quantization-aware-режиме — при вычислении лоссов для эмбеддингов, авторы одновременно вычисляли их для квантизованных в int8-эмбеддингов. В результате, полученные эмбеддинги можно квантизовать в int8 (отмасштабировать в интервал [-127, 128] и округлить), хранить и использовать практически потери качества.
Также в тренировке эмбеддингов использовался подход матрёшки, при котором лоссы применяются не только к эмбеддингам целиком, но и по частям к их первым 32, 64, 128, 256 и 512 элементам. Благодаря этому каждый кратный степени двойки «подсрез» эмбеддинга — тоже эмбеддинг (хоть и худшего качества). При работе с большой базой документов можно, например, брать только первые 128 элементов эмбеддинга вместо 1024 и хранить только их. Суммарно можно сократить размер эмбеддингов базы документов в 10–50 раз.
Во-вторых, в силу архитектуры модель очень гибка в применении. И документ, и запрос могут быть не только одним изображением или текстом, но и их произвольной последовательностью. Довольно большое окно контекста (32К) токенов позволяет обрабатывать 10–20 страниц изображений вместе с текстом.
Также интересная фича таких моделей как класса — наличие инструкции. Мультимодальные семантические эмбеддинги доступны всем и каждому как минимум с момента релиза CLIP (5 лет назад!), но способ вычисления эмбеддинга почти всегда был «зашит» в модель. Для эмбеддеров на основе LLM/VLM можно в инструкции указать, что важно в «кодировании» документов и запросов. Например, в случае поиска по картинкам можно инструктировать модель фокусироваться на стиле изображения или, наоборот, на содержимом — и получить эмбеддинги, поиск по которым будет давать разные результаты.
В итоге у авторов получилась гибкая и эффективная опенсорсная модель для мультимодального поиска. В отчёте приведено много деталей обучения, а в cookbook — примеров использования. Модели такого класса определённо имеют множество применений как в продуктах, так и в рутинных ML-задачах по работе с данными.
Разбор подготовил
CV Time