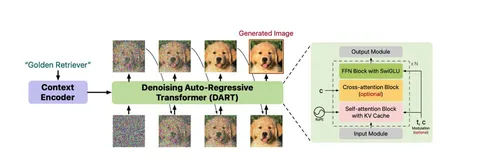
На иллюстрации к посту изображено устройство самой наивной имплементации такой модели — DART. У неё стандартный диффузионный loss, а её единственный существенный недостаток — слишком малый объём входных данных, 4000 токенов. Это накладывает ограничение на скорость обучения модели.
Обойти ограничение помогает модификация DART-AR. При этом один шаг обучения DART-AR занимает столько же времени, как и DART: сходится быстрее, но требует значительно больше времени на инференсе.
Ещё одна модификация — DART-FM, с Flow Matching. Схема усложняется: поверх основного алгоритма DART добавляют несколько прогонов простой нейросети. Эта легковесная «голова» используется на стадии инференса: для итерирования между основными шагами расшумления, чтобы повысить качество генераций.
Статья представляет скорее теоретический, чем практический интерес: инференс занимает слишком много времени, а для сравнения результатов авторы выбрали далеко не самые свежие модели.
Разбор подготовил
CV Time