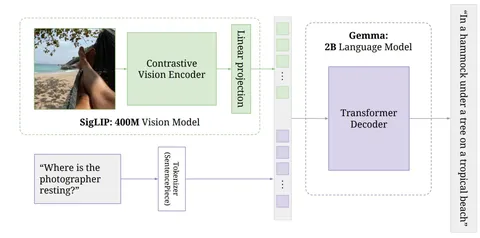
Сегодняшняя статья о PaliGemma. Это VLM, которая разработана на основе технологий семейства моделей PaLI и Gemma. На вход PaliGemma может получать изображения или видео как последовательность кадров.
Модель обучается в четыре этапа:
Unimodal pretraining — на этом этапе PaLI и Gemma обучаются отдельно на данных одного типа.
Multimodal pretraining — здесь вся модель обучается на большом — миллиард сэмплов — наборе мультимодальных задач, таких как объединение визуальных и текстовых данных. Здесь важно, что ни одна часть модели не остаётся «замороженной» — все её компоненты обучаются вместе.
Resolution increase — происходит дополнительное обучение на данных с более высоким разрешением изображений (448 и 896 пикселей).
Трансфер на целевые задачи вроде описания изображений для COCO, VQA для дистанционного зондирования и другие специализированные цели. Этот этап также предполагает дообучение на новых данных, чтобы модель могла решать задачи, для которых она ранее не обучалась.
Важная особенность PaiGemma — использование подхода prefix-LM. Ко всей входной последовательности — изображениям и префиксам — здесь применяется фулл (двунаправленный) аттеншн. Это сделано для того, чтобы большее количество токенов могло активно участвовать в процессе «мышления» с самого начала, так как токены изображения могут обращаться к токенам префикса, которые представляют собой запрос.
Для суффиксов используют кэжуал аттеншн для в авторегресионной генерации. Это позволяет генерировать ответы последовательно, предсказывая следующий токен на основе предыдущих.
В задаче генерации описаний для изображений на датасете COCO PaliGemma выдала результат 141,9 балла при разрешении 224 пикселей и улучшила показатели до 144,6 на 448. В задаче визуальных вопросов и ответов VQAv2 модель продемонстрировала результат в 83,2 и 85,6 балла для разрешения в 224 и 448 пикселей соответственно.
Разбор подготовил
CV Time