Сегодня разберём статью о подходе к обучению и инференсу VLM, вдохновлённом o1-preview от OpenAI.
Авторы начали со сбора 100 тысяч сэмплов из открытых VQA-бенчмарков (и пообещали выложить получившийся датасет!). Потом для этих сэмплов с помощью GPT-4o сгенерировали CoT-синтетику со следующими блоками:
После на этих данных сделали full-finetune поверх Llama-3.2-11B-Vision-Instruct (кстати, всего на восьми H100).
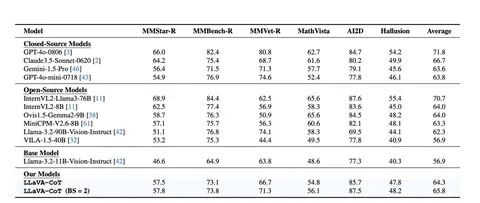
Уже на этом этапе модель стала заметно умнее своего бейзлайна: 56,6 → 63,5 средних попугаев. Но авторы выбили еще полтора попугая за счет собственного inference-time скейлинга: Stage level Beam Search. По сути, это обычный BS. Только ветвление происходит на уровне целых блоков CoT, а не на уровне отдельных предложений.
По замерам авторов, их модель в максимальном сетапе обходит Gemini-1.5-Pro и приближается к Claude3.5-Sonnet (см. табличку). До GPT-4o, правда, еще далековато.
Обзор подготовил
CV Time