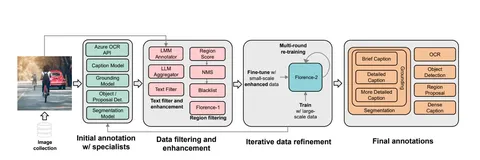
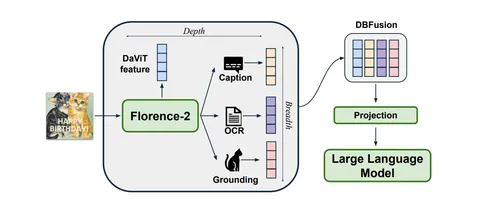
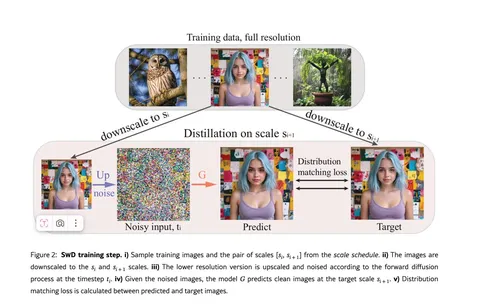
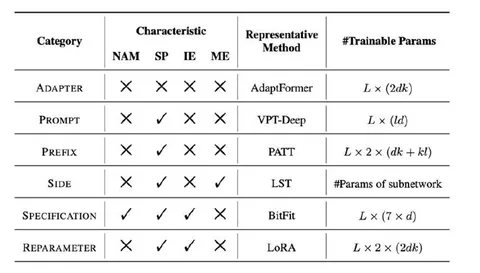
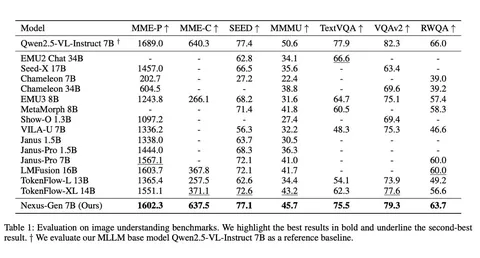
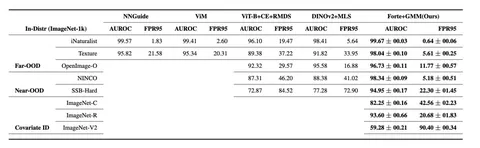
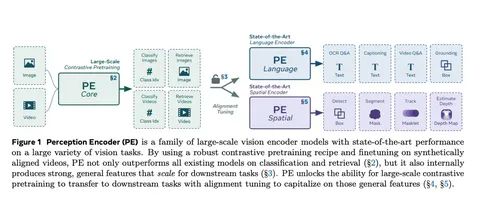
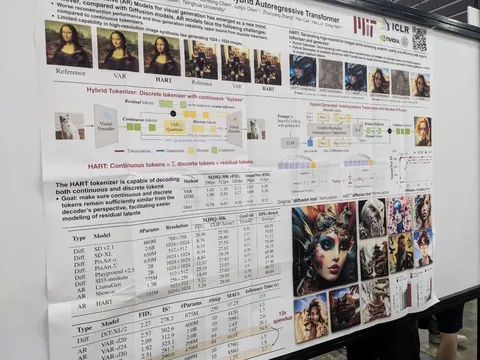
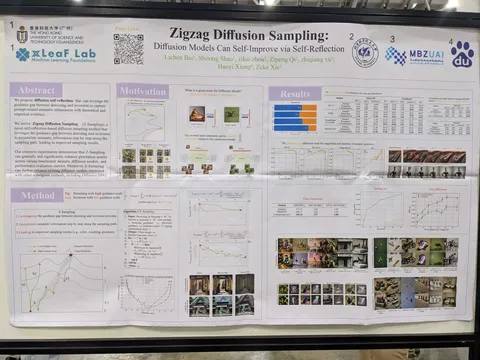
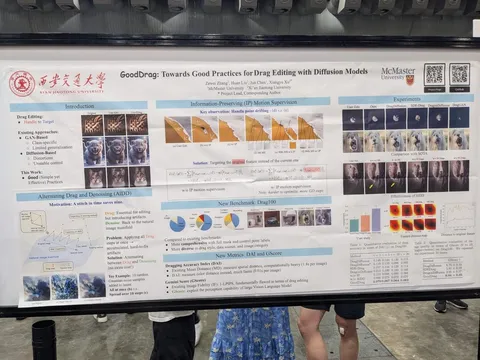
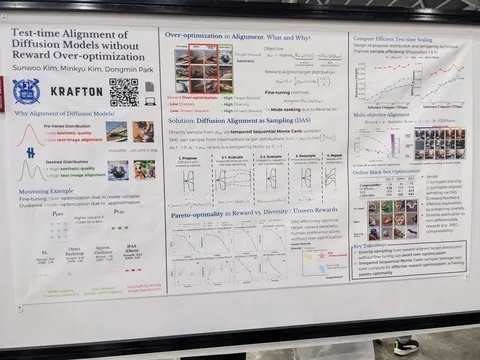
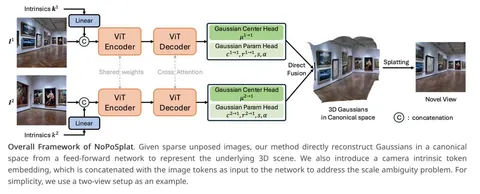
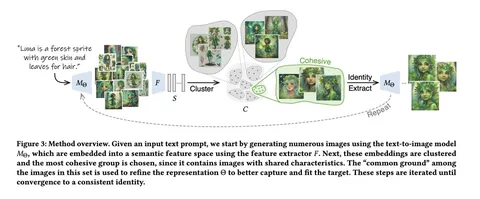
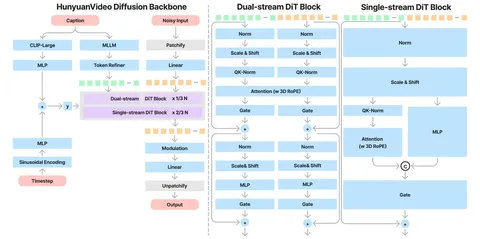
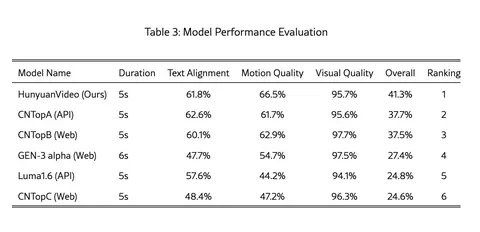
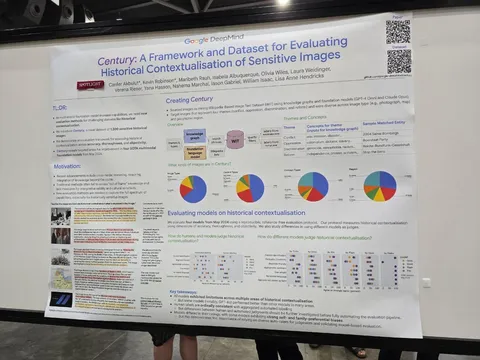
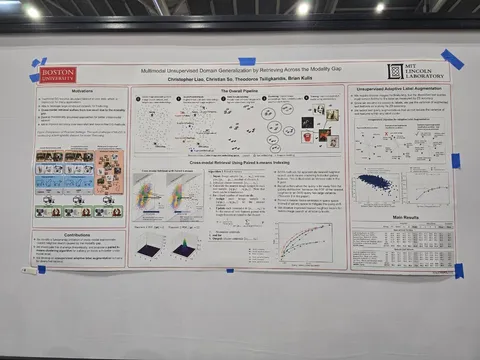
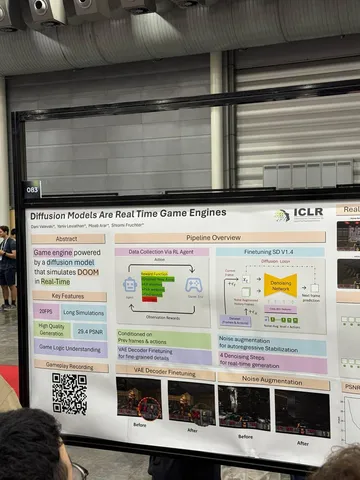
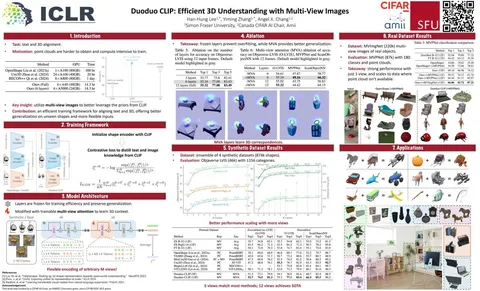
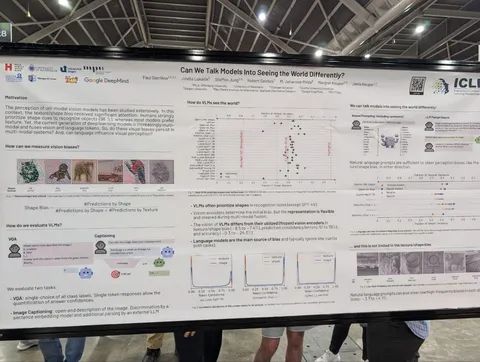
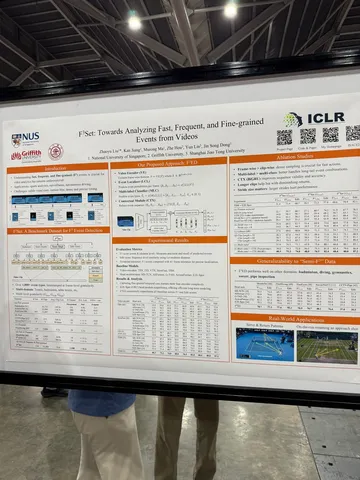
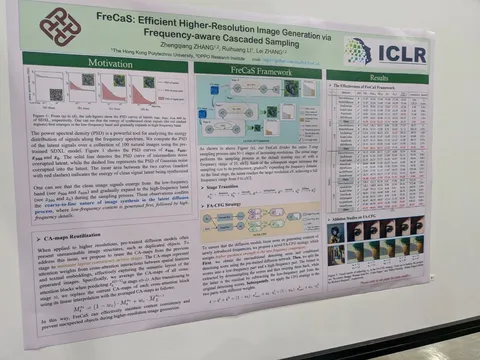
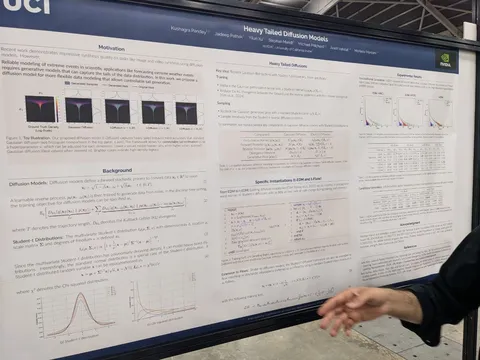
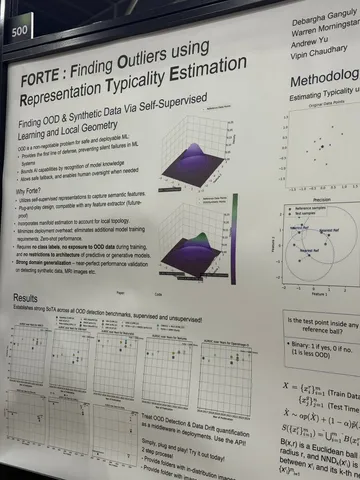
Should VLMs be Pre-trained with Image Data?
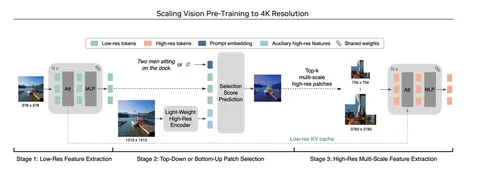
Сегодня разбираем статью о том, как лучше организовать претрейн для VLM. Архитектурных новшеств здесь нет: модель напоминает стандартные опенсорсные VLM вроде LLaVA. Картинка кодируется вижн-энкодером, эмбеддинги прогоняются через несколько MLP-слоёв и подаются вместе с текстовыми эмбеддингами в LLM-декодер.
Главный вопрос статьи: на каком этапе и в каких пропорциях подключать мультимодальные данные, чтобы итоговая модель была сильной и в text-only, и в мультимодальном режимах.
Разберём три интересных аблейшна, представленных в работе.
Когда останавливать LLM-претрейн
Обычно берут полностью обученную LLM (например, на 3–4T токенов) и затем добавляют мультимодальный претрейн со своим LR-шедулером, который часто начинается с warmup. Авторы считают это неэффективным: мы сначала «убиваем» learning rate, а потом снова разгоняем его на мультимодальных данных.
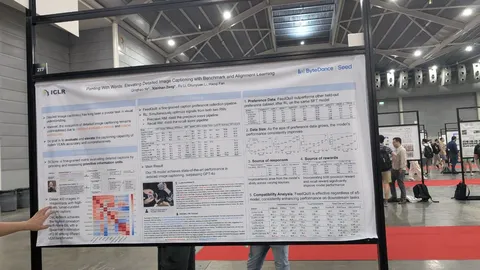
Исследователи пробуют прервать обучение LLM не в самом конце, а на определённом проценте (например, ~80% от шага). Дальше продолжают обучение уже на смеси текстовых и мультимодальных данных, сохраняя текущий learning rate. По представленным VLM метрикам и отдельно text-only-числам, такой вариант даёт лучше результаты, чем стратегия «сначала — до конца LLM, потом — мультимодальность».
Соотношение текстовых и мультимодальных данных
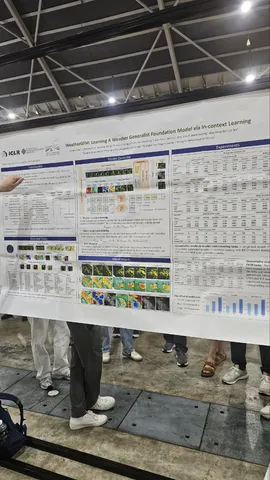
Во многих открытых моделях текстовые и мультимодальные данные миксуют на претрейне VLM, однако аблейшенов не дают. В статье показано, что оптимально брать в претрейн 10–20% мультимодальных данных.
Это можно объяснить качеством датасета: картинки проще, но сами мультимодальные пары нередко «грязные», особенно в опенсорсе. Исходя из практики, мы тоже видим необходимость подбирать соотношение, однако это сильно зависит от качества данных и представленных в них доменов.
Инструктивность и SFT-эпохи
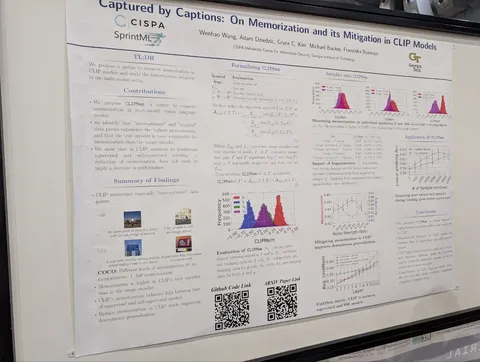
В классическом VLM-pretrain нет инструктивности — модели просто описывают картинки. В последнее время часть инструктивных примеров добавляется уже на претрейне, и это работает. У авторов эффект почти незаметен, скорее всего, из-за слабого датасета (устаревшие LLaVA-данные) и малого количества инструктивных данных.
Ещё одно наблюдение связано с количеством эпох на SFT. Авторы пишут, что в их случае оптимальны четыре эпохи. При данных среднего качества выводы ограниченные и вряд ли могут быть перенесены на любую модель, однако результат полезный. По нашему же опыту — если данные хорошие, дополнительные эпохи действительно помогают.
В целом статья скорее систематизирует наблюдения, чем открывает новое, но её результаты подтверждают, как важно грамотно комбинировать текст и мультимодальность и где именно стоит искать улучшения.
Разбор подготовил❣ Владислав Смирнов
CV Time
Сегодня разбираем статью о том, как лучше организовать претрейн для VLM. Архитектурных новшеств здесь нет: модель напоминает стандартные опенсорсные VLM вроде LLaVA. Картинка кодируется вижн-энкодером, эмбеддинги прогоняются через несколько MLP-слоёв и подаются вместе с текстовыми эмбеддингами в LLM-декодер.
Главный вопрос статьи: на каком этапе и в каких пропорциях подключать мультимодальные данные, чтобы итоговая модель была сильной и в text-only, и в мультимодальном режимах.
Разберём три интересных аблейшна, представленных в работе.
Когда останавливать LLM-претрейн
Обычно берут полностью обученную LLM (например, на 3–4T токенов) и затем добавляют мультимодальный претрейн со своим LR-шедулером, который часто начинается с warmup. Авторы считают это неэффективным: мы сначала «убиваем» learning rate, а потом снова разгоняем его на мультимодальных данных.
Исследователи пробуют прервать обучение LLM не в самом конце, а на определённом проценте (например, ~80% от шага). Дальше продолжают обучение уже на смеси текстовых и мультимодальных данных, сохраняя текущий learning rate. По представленным VLM метрикам и отдельно text-only-числам, такой вариант даёт лучше результаты, чем стратегия «сначала — до конца LLM, потом — мультимодальность».
Соотношение текстовых и мультимодальных данных
Во многих открытых моделях текстовые и мультимодальные данные миксуют на претрейне VLM, однако аблейшенов не дают. В статье показано, что оптимально брать в претрейн 10–20% мультимодальных данных.
Это можно объяснить качеством датасета: картинки проще, но сами мультимодальные пары нередко «грязные», особенно в опенсорсе. Исходя из практики, мы тоже видим необходимость подбирать соотношение, однако это сильно зависит от качества данных и представленных в них доменов.
Инструктивность и SFT-эпохи
В классическом VLM-pretrain нет инструктивности — модели просто описывают картинки. В последнее время часть инструктивных примеров добавляется уже на претрейне, и это работает. У авторов эффект почти незаметен, скорее всего, из-за слабого датасета (устаревшие LLaVA-данные) и малого количества инструктивных данных.
Ещё одно наблюдение связано с количеством эпох на SFT. Авторы пишут, что в их случае оптимальны четыре эпохи. При данных среднего качества выводы ограниченные и вряд ли могут быть перенесены на любую модель, однако результат полезный. По нашему же опыту — если данные хорошие, дополнительные эпохи действительно помогают.
В целом статья скорее систематизирует наблюдения, чем открывает новое, но её результаты подтверждают, как важно грамотно комбинировать текст и мультимодальность и где именно стоит искать улучшения.
Разбор подготовил
CV Time
2 322 просмотров · 26 реакций
Открыть в Telegram · Открыть пост на сайте