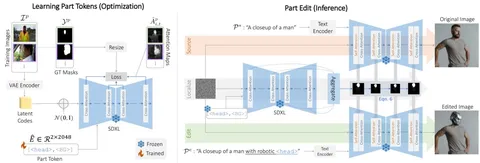
Сегодня разбираем статью о редактировании изображений. Авторы показывают, как с помощью предобученной диффузионной модели SDXL можно детально изменять заданные сегменты на изображении.
Предложенный метод требует обучения токенов частей картинки на датасете, где для каждой картинки и целевого токена есть маска, соответствующая области, которую нужно изменить. В промпт подаются два токена, например: <head> (токен головы) и <BG> (бэкграунд для головы). Причём токен бэкграунда (<BG>) уникален для каждого целевого токена.
Дальше токены обучаются так, чтобы маски аттеншна в SDXL давали маски сегментации нужной части картинки. При этом сама диффузионная модель остается замороженной, обучаются только токены.
Авторы отдельно изучают, в каком диапазоне (от 0 до 50, где 0 — почти чистое изображение, а 50 — максимально зашумлённое) лучше брать усреднение. При обучении на таймстемпах [50, 40] маски получаются некачественные. В диапазоне [30, 20] результат лучше. При [10, 0] — чуть хуже, чем на среднем.
Когда эмбеддинги выучены, происходит редактирование. В случае с синтетическими изображениями используются три ветки:
1. Генерация исходного синтетического изображения. Например, по промпту "A closeup of a man" в качестве промпта подаётся, например, "A closeup of a man", где мы хотим заменить голову человека на голову робота. SDXL генерирует изображение и при этом сохраняется траектория — промежуточные латенты для каждого таймстемпа.
2. Средняя часть архитектуры работает как сегментатор: в SDXL подаются только два выученных эмбеддинга: части, которую нужно отредактировать и бэкграунда. В нашем примере это будет <head> и <BG>.
Для каждого таймстемпа собираются все маски аттеншна со всех слоёв (предварительно приводятся к одному размеру и агрегируются). Затем применяется алгоритм OTSU, который вычисляет локальный порог: если значение больше порога — это единица, если меньше — ноль, а в промежутке от 1/2K до 3/2K маска просто сохраняется.
3. Генерация отредактированного изображения: через SDXL прогоняются выученные эмбеддинги того, что нужно заменить (например, чтобы получить "A closeup of a man with robotic <head>").
На этапе редактирования фичемапы с исходного и редактирующего прогона блендятся с помощью предобработанных масок аттеншна из второй ветки. В конце прогона получается отредактированное изображение: нужная часть изменена, остальное — как в оригинале.
Решение применимо не только к синтетическим, но и к реальным изображениям: с помощью методов инверсии LEDIT++ и EF-DDPM получают латенты, а с помощью BLIP2 — промпт-описание исходной картинки.
В сравнениях с другими подходами в качестве метрики используется Alpha-CLIP: по маске определяется область редактирования, а с помощью CLIP считается, насколько результат соответствует заданному промпту. Как водится — по всем метрикам результаты превосходят конкурентов.
Разбор подготовил
CV Time