Сегодня разберём работу Infinity-MM и описанную в ней модель Aquila-VL-2B. Эта маленькая VLM с двумя миллиардами параметров интересна тем, что смогла обойти в своём классе Qwen и InternVL, которые редко уступают первые позиции лидербордов. Расскажем, как в топе MMBench оказалась неизвестная модель и почему иногда бенчмарки могут искажать реальную ситуацию.
Работа представляет собой репорт о проведённом эксперименте. Материал не содержит наукоёмких изменений в пайплайне обучения или архитектуре модели. Авторы сосредоточены на теме данных и отвечают на вопрос: как при ограниченных ресурсах стать SOTA VLM, пусть даже не в самом популярном классе маленьких моделек.
Один из ключевых тезисов: при обучении VLM имеет смысл масштабировать объём SFT-данных. С этой целью авторы собрали всё доступное из опенсорса и получили датасет из нескольких десятков миллионов инстрактов, а также сгенерировали в дополнение небольшую часть синтетики. Все данные фильтровались, проходили дедупликацию и проверку на разнообразие. Итоговый мультимодальный датасет — это и есть Infinity-MM из названия статьи.
Из-за ограничения в вычислительных ресурсах исследователи использовали для генерации и чистки датасета опенсорсные модели, в частности активно прибегали к помощи Qwen.
Пайплайн для генерации синтетических данных выглядит следующим образом:
— Собирается база изображений, их размечают с помощью опенсорс-модели, которая тегирует объекты на картинке.
На основе тегов формируется дерево типов задач, для которых целесообразно создавать инстракты.
— Опенсорсными моделями (преимущественно MiniCPM и Qwen) генерируют инстракт по картинке, тегу и тематике. Происходит автофильтрация через эту же модель (ей дают сгенерированный инстракт и спрашивают, насколько он валиден).
— Затем получают ответ по синтетическому инстракту — та же модель снова отвечает на вопрос, который сама придумала.
— Следующий шаг — фильтрации ответа. Тут интересное решение: опенсорсная модель считает лосс по полученной паре и, если он высокий, пример исключается. Так исследователи автоматически отфильтровали 5% самых «шумных» данных.
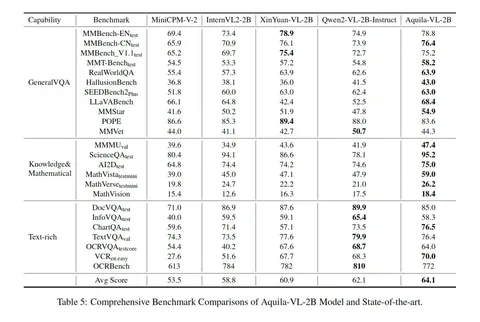
Этих несложных манипуляций хватило, чтобы обогнать модели, которыми авторы генерировали и фильтровали свои данные. Скорее всего, так произошло, потому что синтетику целенаправленно собирали под конкретный бенчмарк (MMBench). И в таком случае модель может непредсказуемо вести себя на других задачах.
Можно сделать вывод, что бенчмарки лучше использовать исключительно как «градусник», чтобы следить за изменениями в области. А вот для оценки эффективности моделей надёжнее ориентироваться на SBS-замеры (Side-by-Side), которые позволяют проводить прямое сравнение в реальных условиях.
А как вы оцениваете опыт Aquila-VL-2B и доверяете ли ещё бенчмаркам?
Обзор подготовил
CV Time