Разбираем статью UniReal от исследователей из университета Гонконга. Редактирование изображений — обширная область, в которой есть разнообразные подходы, в частности, известные ControlNet и InstructPix2Pix. Однако в случае с UniReal авторы хотели создать универсальную модель, способную из коробки решать разные типы задач.
На тизерной странице есть примеры её работы. Модель может изменить фон исходной картинки, убрать или заменить изображение, добавить новые объекты, поменять стиль, создать композицию из объектов.
Архитектура
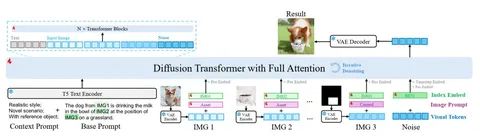
Модель построена на диффузионном трансформере с Full Attention. Архитектура включает следующие компоненты:
— энкодер T5 для обработки текстовых токенов;
— VAE-энкодеры для изображений;
— специальные токены для работы с несколькими изображениями (например, IMG1 для входного изображения и RES1 для результирующего).
Картинки могут выполнять разную роль: быть фоновым изображением (canvas image), давать сигнал, вроде указания границ или глубины (control image), или просто участвовать в качестве объекта на сцене (asset image). Для каждой категории изображений есть обучаемые токены (learnable category embeddings). Они добавляются вместе с картинкой, как промпт.
Авторы используют обучаемые контекстные промпты с несколькими сценариями: реалистичными, синтетическими, статическими, динамическими, а также с референсным объектом.
Данные
Качественных датасетов для редактирования изображений довольно много, например: InstructPix2Pix, UltraEdit, VTON-HD. Но все же их оказалось недостаточно, поэтому исследователи добавили этап обучения на видеоданных. Использовали два типа предобучения:
— С помощью видеоклипов, из которых случайным образом выбирались два кадра, а также добавлялись описания происходящего в клипе. Для генерации синтетических описаний применяли модель GPT-4 mini.
— Генерация описаний изображений с привязкой к границам объектов (bounding boxes) с помощью VLM Kosmos-2. Эти границы комбинировались с Segment Anything Model (SAM) для получения масок. Так создавалась синтетическая разметка видео для задач вставки объектов и заполнения отсутствующих частей изображения (inpainting).
Модель предобучалась на этой смеси: сначала на видеоданных, затем на публичных датасетах. Исследователи делают акцент на том, что для финального результата были важны все компоненты.
Результаты
Сравнение на бенчмарках EMU Edit и MagicBrush в задачах редактирования изображений показало, что UniReal успешно справляется со сложными задачами, такими как добавление и удаление объектов, в то время как базовые модели допускают в них ошибки.
Для генерации референсных объектов на фоне модель сравнивается с Textual Inversion, DreamBooth, BLIP-Diffusion и другими. Не во всех случаях она превосходит конкурентов по метрикам, но показывает хорошие результаты в SBS-замерах.
Сейчас модель неплохо работает с двумя-тремя изображениями, но для генерации на десяти и более изображениях требуется больше данных и доработка архитектуры.
Обзор подготовил
CV Time