Сегодня — статья о ранжировании рекламы. Как и в других рекомендательных системах, в нём 3 стадии:
• Retrieval — отбор объявлений из баз, необязательно с помощью ML (~миллионы объявлений).
• Ранняя стадия ранжирования (~тысячи объявлений).
• Финальное ранжирование (~сотни объявлений).
Value считают на обоих этапах ранжирования, а итоговую оценку получают в финале. Учитывают:
• ставку рекламодателя;
• кликовые/конверсионные прогнозы;
• качество рекламы, оно же фидбек. Например, клик по крестику говорит, что объявление нерелевантно.
Проблемы ранней стадии ранжирования
Частый кейс — есть баннер, который получил бы высокую оценку, попал к пользователю и принёс конверсию, но первая модель его отсеяла. Виноваты ограничения по железу — лёгкая модель всегда хуже финальной. Отсюда же неконсистентность на уровне критериев оценки.
Selection bias возникает из-за несовпадения тренировочных и реальных данных. В обучение идут баннеры с показами, а на тесте модель впервые видит свежие. Из-за этого показанные ранее баннеры имеют несправедливое преимущество.
Решение
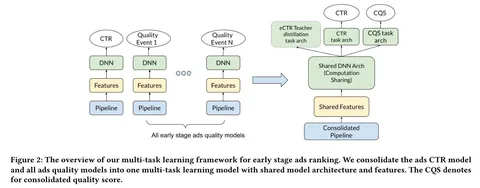
Фреймворк с мультитаргет-архитектурой. В нём есть shared-часть — она выдаёт эмбеддинги, которые идут в 3 головы:
• Первая предсказывает CTR.
• Во второй происходит дистилляция — главная фишка статьи. Модель с нижних стадий обучают на разметке моделей с финальной стадии ранжирования
• Третья — Consolidated Quality Score — учится на целевые действия кроме кликов: результаты опросов, долгие конверсии и др. Для каждого баннера считается их вероятность, а таргет берётся из финальной стадии.
Финальная модель обучается на сумму loss’ов — важно аккуратно подбирать веса, чтобы ничего не просело.
Мультитаргетная архитектура позволяет экномить ресурсы и не сильно терять в качестве. Проблему selection bias решают, добавляя в датасет негативы.
Оценивают симулятором — он считает вероятный топ в оффлайне. Так получают golden-сет, с которым сравнивают результаты прода.
@RecSysChannel
Разбор подготовила